
ROAD: Optimize AI Prompts Without Manual Datasets
ROAD: Optimize AI Prompts Without Manual Datasets
Introduction
Optimizing Large Language Model (LLM) systems is rarely a straightforward path. While recent academic research has provided powerful algorithms for automated prompt engineering, applying them within the constraints of an active engineering organization reveals a critical bottleneck: the data itself.
In this article, we introduce ROAD, a workflow developed by our team to bridge the gap between academic optimization algorithms and the rapid, iterative needs of real-world software development.
The Foundation: What is GEPA?
To understand our approach, we must first look at the core technology we built upon. GEPA (Genetic-Pareto) is a state-of-the-art prompt optimizer designed to solve the "sample efficiency" problem in LLM training.
Traditionally, adapting an LLM to a specific task required Reinforcement Learning (RL) methods like GRPO, which often necessitated thousands of rollouts to learn effectively. GEPA changes this paradigm by treating prompts as "genetic" candidates. It uses natural language reflection to diagnose why a prompt failed, proposes "mutations" (edits) based on that feedback, and maintains a "Pareto frontier" of diverse, high-performing prompts rather than searching for a single global optimum.
Essentially, GEPA is an evolution engine: it learns high-level rules from trial and error, identifying distinct strategies that work for specific problem types.
The Pain Point: The "Refined Dataset" Bottleneck
While GEPA is technically impressive, it relies on a fundamental assumption that is often a luxury in production environments: the existence of a high-quality, pre-labeled training set.
In the standard GEPA methodology, the system requires a curated training dataset consisting of inputs and verifiable evaluation metadata (like gold answers or unit tests) to drive the evolutionary loop.
However, as we build novel agents and complex tools within our organization, we rarely have the time or resources to curate a refined dataset upfront. We are often working with messy production logs, evolving edge cases, and failure modes that don't fit neatly into a static Q&A format. We cannot afford to pause development to manually label thousands of examples just to start optimizing.
The friction lies in data preparation. The academic requirement for pristine data conflicts with the rapid "fail-fix-deploy" cycle required in our engineering workflow.
Our Solution: The ROAD Workflow
To address this, our team developed ROAD. This is not just an algorithm, but a pragmatic workflow designed to automate the failure analysis loop without requiring a perfect dataset from day one.
Instead of relying on static training data, ROAD treats optimization as a dynamic investigation:
- Benchmarking & Filtering: We start by running the model (the "Contestant") against a benchmark or live environment. Crucially, we discard the successes and filter strictly for the failure cases.
- Automated Root Cause Analysis: We employ a second LLM (the "Analyzer") to perform a deep-dive failure analysis on each mistake, determining exactly why the Contestant failed and defining the corrective action required.
- Holistic Pattern Recognition: Rather than patching errors individually, we aggregate these analyses. A third LLM (the "Optimizer") reads the entirety of the failure reports to identify high-level failure patterns, outliers, and commonalities. The Optimizer’s output isn't just a text summary—it is a comprehensive Decision Tree that maps out the logic gaps the model is falling into.
- Targeted Evolution: Finally, a "Coach" LLM integrates this Decision Tree into the system prompt—either appending it as a reasoning guide or rewriting the core instructions entirely—before looping back to benchmarking.
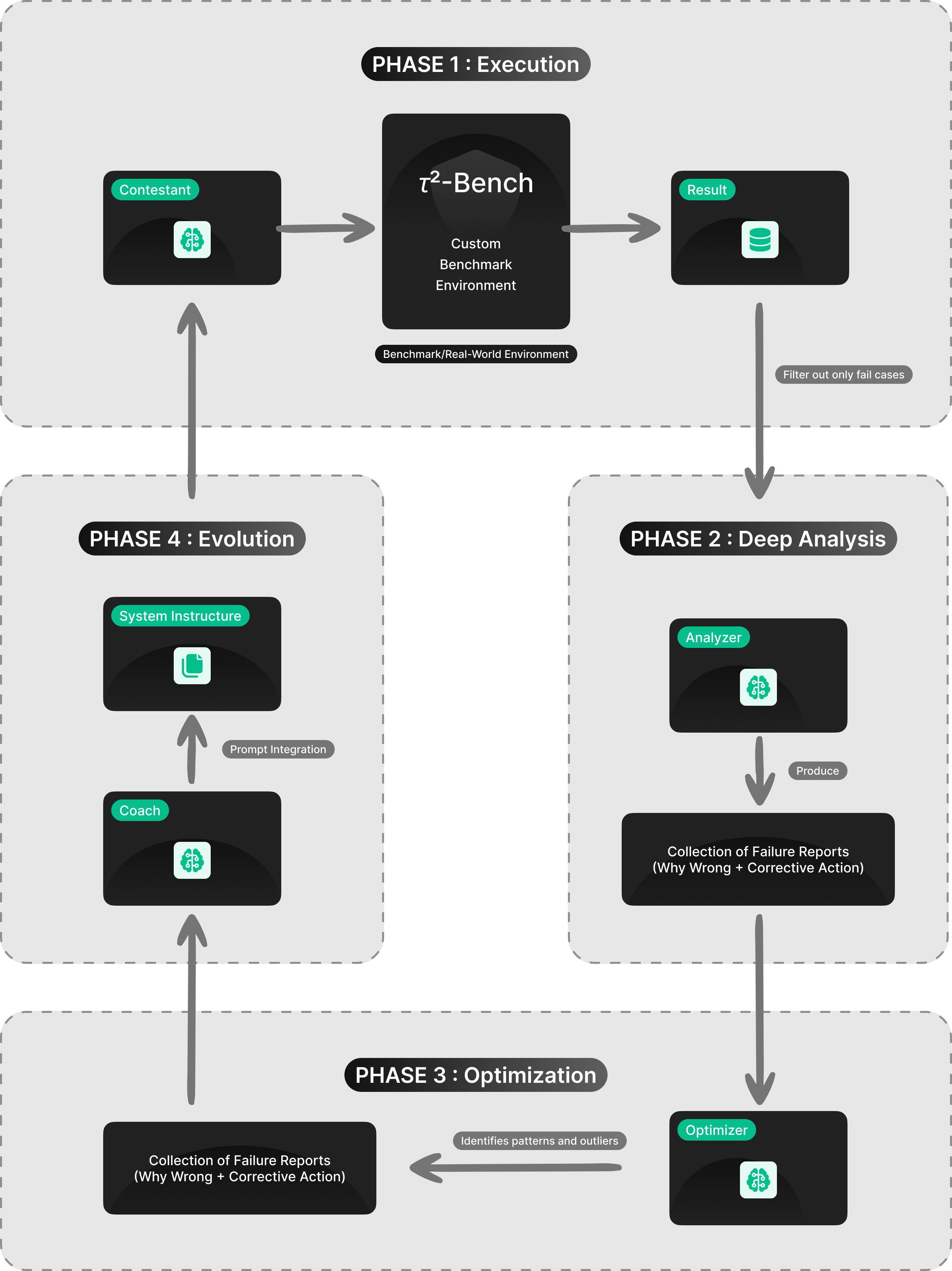
ROAD transforms prompt engineering from a manual guessing game into a structured, automated process of failure pattern extraction. By focusing purely on how the model fails, we can evolve system prompts that are resilient to the specific complexities of our real-world data.
Performance Results
To validate the ROAD workflow, we tested the methodology across two distinct environments: a standardized academic benchmark (𝜏²-bench) and a live production engine (Accentix KM). In both scenarios, the automated loop of failure analysis and decision tree evolution yielded significant performance gains over the base prompt.
1. Academic Benchmarking: 𝜏²-bench (Retail Domain)
We first evaluated ROAD using 𝜏²-bench, a rigorous framework designed to test conversational agents in dual-control environments where both the user and agent have agency. Specifically, we focused on the Retail domain, which demands complex tool usage for tasks like order modifications and refund processing.
As shown in the chart below, we benchmarked performance across different models, including o4-mini and Qwen3-4B-Thinking-2507. Focusing on the Qwen3-4B-Thinking-2507 model, the agent began with a baseline performance score of approximately 53. By running the ROAD loop, filtering failures, analyzing root causes, and injecting optimized decision trees back into the system prompt, we achieved a significant performance boost.
.png)
After applying ROAD, the Qwen3-4B-Thinking-2507 agent's performance score climbed to roughly 63. This ~19% relative improvement highlights the Coach LLM's ability to successfully patch logic gaps in the agent's reasoning. Additionally, the o4-mini model showed similar gains, improving from a baseline of ~68 to nearly 78, demonstrating that the framework is effective even on stronger, state-of-the-art models.
Example: System Prompt Evolution
To visualize the 19% performance gain for Qwen3-4B-Thinking-2507, we compare the baseline instructions against the optimized Decision Tree injected by ROAD after 6 iterations.
Before: Vague Prose (Baseline)
The instructions are conversational and open to interpretation. The agent often failed here because it didn't know the specific order of operations for complex tasks.
.png)
After: Strict Decision Tree (Iteration 6)
The Coach LLM injected a numbered operational framework. Note the strict logic for sequencing actions (Address --> Items) and safety checks (Literal "YES").
.png)
Key Highlights in this Example:
- Ambiguity Removal: "Authenticate the user" (Before) became a strict 1.1 / 1.2 / 1.3 step-by-step workflow.
- Logic Injection: The agent previously didn't know which to update first (address or items). The After prompt explicitly enforces a sequence (5B.5) to prevent database errors.
- Safety Guardrails: The generic "obtain confirmation" became a strict requirement for a literal "YES", reducing accidental executions.
2. Real-World Application: Accentix KM Engine
While academic benchmarks provide a controlled testing ground, the true validation of ROAD lies in its deployment within a live production environment. We applied the workflow to the Accentix Knowledge Management (KM) engine, a system responsible for retrieving precise documentation and answers for complex user queries.
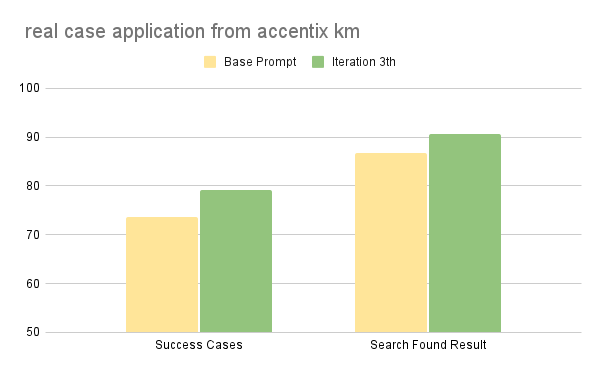
Unlike the academic benchmark, which required six iterations to mature, our real-world deployment saw rapid convergence. As illustrated in the chart below, within just 3 iterations, we achieved measurable improvements across our primary KPIs:
- Success Cases (73.6% --> 79.2%): The overall task success rate improved by 5.6%. This indicates that the Decision Tree generated by the Optimizer effectively resolved ambiguity in user intents that previously led to dead ends.
- Search Found Result (86.8% --> 90.6%): Crucially, the agent's ability to retrieve valid search results increased by 3.8%. This suggests our failure analysis successfully diagnosed suboptimal query patterns (such as overly specific keyword usage), allowing the Coach to update the prompt with broader, more robust search strategies.
This rapid improvement confirms that ROAD effectively adapts to the specific, often "messy" edge cases found in production data, correcting logic gaps that standard benchmarks might miss.
Case Study 1: Contextual Query Reformulation
The Challenge: The user provided input across multiple turns. The "Before" model failed to carry the context from the first question ("disability") into the second question ("private hospital"), resulting in a search for the generic term "Private."
- Turn 1 Context: "How much is the outpatient fee for disability cases?"
- Turn 2 Input: "Private hospital."

Case Study 2: Hallucination Prevention & Scope Management
The Challenge: The user asked a speculative, opinion-based question about the future financial solvency of the Social Security fund ("Will the money run out in 20 years?"). The "Before" model attempted to answer with generic info, while the "After" model correctly identified this as out-of-scope.
- Question: "I heard news that if new people don't contribute, the Social Security fund will run out... will I still get money when I'm 60?"
.png)
Conclusion
In the race to production, speed isn't just a metric, it is survival. The transition to the ROAD workflow proves that we no longer have to choose between deploying fast and deploying smart. We can do both.
While the original GEPA algorithm revolutionized academic benchmarks by drastically reducing sample requirements compared to traditional Reinforcement Learning, ROAD takes the next leap: Zero-Shot Data Curation. We achieved a 5.6% jump in Success Rate and a 3.8% boost in Search Accuracy not by spending weeks labeling data, but by simply letting the system learn from its own mistakes.
In just three automated iterations, ROAD delivered production-grade improvements with zero manual intervention.
Trading Tokens for Time: The Ultimate ROI
Critics might point to the "Token Tax", the computational cost of using three separate LLMs to analyze, optimize, and coach. We call it Strategic Leverage.
We are effectively trading cheap compute credits for invaluable engineering hours. Instead of burning your lead engineer's time on tedious log analysis and prompt tweaking, ROAD automates the heavy lifting. It identifies logic gaps and patches "stupid" errors in hours, not days. This isn't an expense; it is an investment in velocity.
The Verdict
ROAD is the ultimate accelerator for the "Cold Start" problem. It is the bridge that takes you from a messy, unrefined prototype to a robust, self-correcting agent. While it may not hit the theoretical ceiling of a massive 20,000-rollout RL training run, it solves the problem that actually matters to businesses: Getting a high-quality agent into production, now.
We are done with the days of manual prompt grinding. With ROAD, we aren't just building agents; we are building systems that build themselves.
Collaborate and partner with our AI Lab at Amity Solutions here
