
ROAD: ปรับ Prompt AI โดยไม่พึ่งพาชุดข้อมูลแบบ Manual
ROAD: ปรับ Prompt AI โดยไม่พึ่งพาชุดข้อมูลแบบ Manual
บทนำ
การเพิ่มประสิทธิภาพระบบโมเดลภาษาขนาดใหญ่ (LLM) ไม่ใช่เรื่องง่ายเสมอไป แม้ว่างานวิจัยทางวิชาการล่าสุดจะนำเสนออัลกอริทึมที่ทรงพลังสำหรับ Automated Prompt Engineering แต่การนำมาประยุกต์ใช้ภายใต้ข้อจำกัดขององค์กรทางวิศวกรรมที่ทำงานจริงกลับเผยให้เห็นคอขวดที่สำคัญ นั่นคือ "ตัวข้อมูลเอง"
ในบทความนี้ เราจะแนะนำ ROAD เวิร์กโฟลว์ที่ทีมของเราพัฒนาขึ้นเพื่อเชื่อมช่องว่างระหว่างอัลกอริทึมการเพิ่มประสิทธิภาพทางวิชาการ กับความต้องการในการพัฒนาซอฟต์แวร์ในโลกแห่งความเป็นจริงที่ต้องอาศัยความรวดเร็วและการทำงานซ้ำๆ (Iterative)
พื้นฐาน: GEPA คืออะไร?
เพื่อให้เข้าใจแนวทางของเรา เราต้องย้อนกลับไปดูเทคโนโลยีหลักที่เราใช้ต่อยอดคือ GEPA (Genetic-Pareto) ซึ่งเป็นเครื่องมือเพิ่มประสิทธิภาพ Prompt ระดับแถวหน้า ที่ออกแบบมาเพื่อแก้ปัญหา
"ประสิทธิภาพของข้อมูลตัวอย่าง" (Sample Efficiency) ในการฝึกฝน LLM
แต่ก่อน การปรับตัวของ LLM สำหรับงานเฉพาะทางต้องใช้วิธีการเรียนรู้แบบเสริมกำลัง (Reinforcement Learning - RL) เช่น GRPO ซึ่งมักต้องใช้การประมวลผล (Rollouts) หลายพันครั้งเพื่อให้เรียนรู้ได้อย่างมีประสิทธิภาพ แต่ GEPA เปลี่ยนวิธีใหม่โดยมองว่า Prompt เป็นเสมือน "ตัวเลือกทางพันธุกรรม" (Genetic Candidates) โดยระบบจะใช้การวิเคราะห์ด้วยภาษาธรรมชาติเพื่อหาเหตุผลว่าทำไมคำสั่ง (Prompt) ถึงไม่ได้ผล จากนั้นจะเสนอการแก้ไข (Mutations) ตามผลวิเคราะห์นั้น และรักษาตัวเลือกคำสั่งที่หลากหลายและมีประสิทธิภาพสูงไว้ในหลายๆ รูปแบบ (Pareto frontier) แทนที่จะพยายามหาคำสั่งที่สมบูรณ์แบบเพียงหนึ่งเดียว
โดยพื้นฐานแล้ว GEPA คือกลไกการพัฒนาตนเองที่เรียนรู้หลักการระดับสูงจากการทดลองทำจริง ทำให้สามารถค้นพบกลยุทธ์ที่หลากหลายและเหมาะสมกับโจทย์แต่ละประเภทได้อย่างแม่นยำ
Pain Point: คอขวดของ "ชุดข้อมูลที่ขัดเกลาแล้ว"
แม้ว่า GEPA จะดูเก่งกาจในเชิงเทคนิคแค่ไหน แต่มันก็ตั้งอยู่บนเงื่อนไขสำคัญที่หาได้ยากมากในหน้างานจริง นั่นคือเราต้องมีชุดข้อมูลตัวอย่างที่ถูกคัดแยกและเฉลยคำตอบไว้อย่างถูกต้องแม่นยำเตรียมไว้รออยู่แล้ว
ในระเบียบวิธีมาตรฐานของ GEPA ระบบต้องการชุดข้อมูลฝึกฝนที่ถูกคัดสรรมาอย่างดี ซึ่งประกอบด้วย
“ข้อมูลนำเข้า (Inputs)” และ “เกณฑ์การวัดผลที่พิสูจน์ได้ (Verifiable evaluation metadata)” (เช่น คำตอบที่เป็นมาตรฐาน หรือ Unit Tests) เพื่อขับเคลื่อนวงจรวิวัฒนาการ
อย่างไรก็ตาม ในขณะที่เราสร้างเอเจนต์ (Agents) ใหม่ๆ และเครื่องมือที่ซับซ้อนภายในองค์กร เรามักเผชิญข้อจำกัดด้านเวลาและทรัพยากร ทำให้ไม่สามารถจัดเตรียมชุดข้อมูลที่ผ่านการปรับปรุงอย่างสมบูรณ์ล่วงหน้าได้ และเรามักจะต้องรับมือกับข้อมูลบันทึกการทำงาน (Logs) ที่ยุ่งเหยิง, เคสประหลาด (Edge cases)ใหม่ๆ ที่เกิดขึ้นตลอดเวลา และรูปแบบความผิดพลาดที่ซับซ้อนเกินกว่าจะสรุปเป็นชุดคำถาม-คำตอบแบบตายตัวได้ เราจะมัวมานั่งเสียเวลาคัดแยกข้อมูลทีละชิ้นเป็นพันๆ รายการไม่ได้ เพราะมันจะทำให้การพัฒนาล่าช้า เราต้องเริ่มปรับจูนระบบให้ทำงานได้ดีขึ้นทันที
อุปสรรคจึงอยู่ที่การเตรียมข้อมูล ข้อกำหนดทางวิชาการที่ต้องการข้อมูลที่สะอาดหมดจดขัดแย้งกับวงจร "ล้มเหลว-แก้ไข-ใช้งาน" (Fail-Fix-Deploy) ที่รวดเร็วในเวิร์กโฟลว์วิศวกรรมของเรา
โซลูชันของเรา: เวิร์กโฟลว์แบบ ROAD
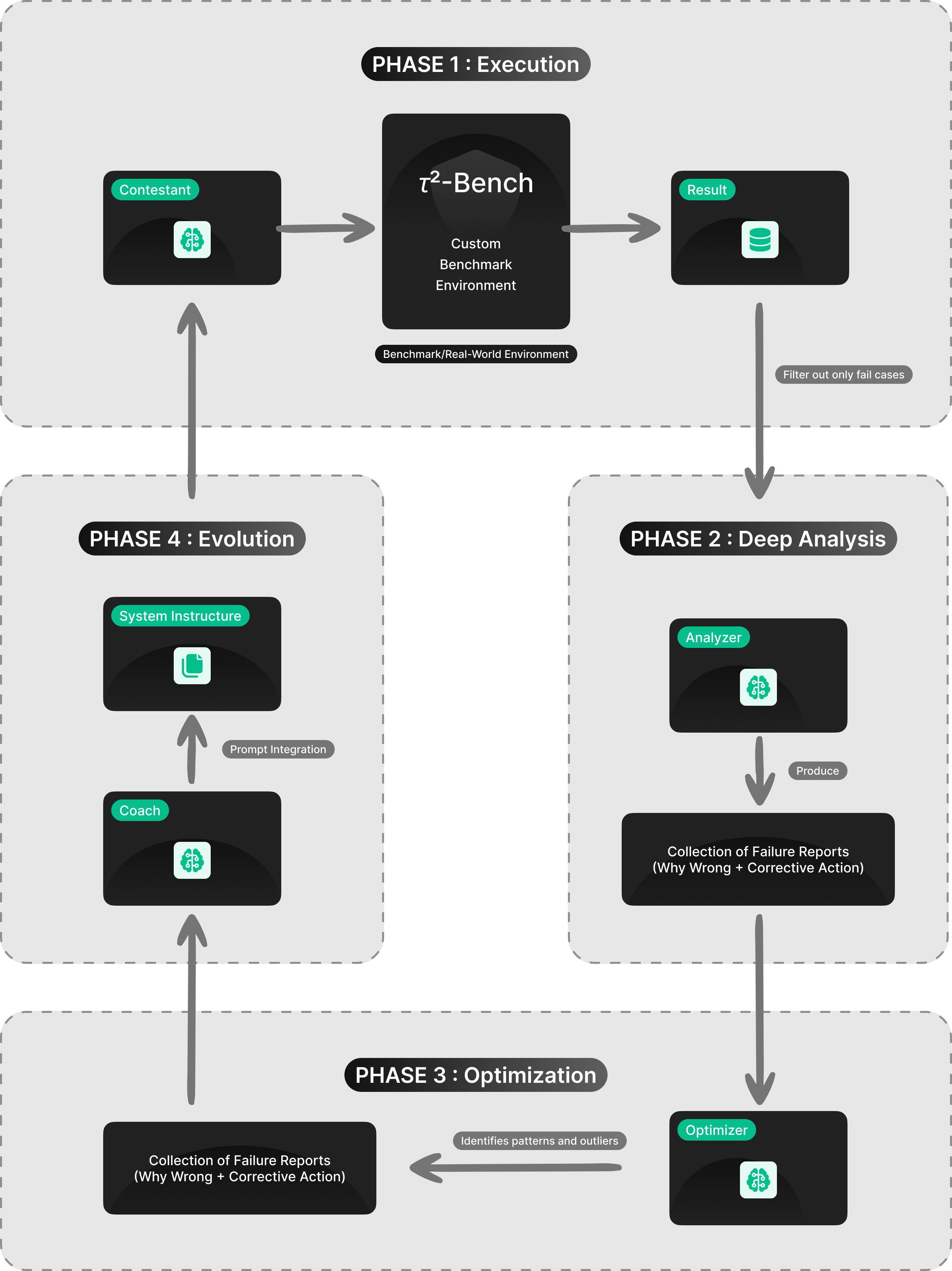
เพื่อแก้ปัญหานี้ ทีมของเราจึงพัฒนา ROAD ขึ้นมา ที่ไม่ใช่แค่อัลกอริทึม แต่เป็นเวิร์กโฟลว์เชิงปฏิบัติที่ออกแบบมาเพื่อวิเคราะห์ความล้มเหลวโดยอัตโนมัติ แบบไม่ต้องมีชุดข้อมูลที่สมบูรณ์ตั้งแต่วันแรก
แทนที่จะต้องพึ่งพาชุดข้อมูลฝึกฝนแบบตายตัว ROAD เปลี่ยนกระบวนการปรับปรุงระบบให้กลายเป็นการสืบสวนเชิงรุกที่ยืดหยุ่นและปรับเปลี่ยนตามสถานการณ์จริง:
- Benchmarking & Filtering: เราเริ่มจากการรันโมเดล (ผู้เข้าแข่งขัน หรือ "Contestant") กับชุดทดสอบหรือสภาพแวดล้อมจริง สิ่งที่สำคัญคือเราจะทิ้งกรณีที่ทำสำเร็จ และคัดกรองเฉพาะกรณีที่ ล้มเหลว เท่านั้นมาใช้งาน
- Automated Root Cause Analysis: เราใช้ LLM ตัวที่สอง (ผู้วิเคราะห์ หรือ "Analyzer") เพื่อวิเคราะห์สาเหตุเชิงลึกของแต่ละข้อผิดพลาด เพื่อระบุว่าทำไม Contestant ถึงพลาด และควรกำหนดวิธีแก้ไขอย่างไร
- Holistic Pattern Recognition: แทนที่จะแก้ไขความผิดพลาดทีละจุด เราจะรวบรวมการวิเคราะห์เหล่านี้เข้าด้วยกัน โดย LLM ตัวที่สาม (ผู้เพิ่มประสิทธิภาพ หรือ "Optimizer") จะอ่านรายงานความล้มเหลวทั้งหมดเพื่อระบุแพทเทิร์นความล้มเหลวในภาพรวม และจุดร่วมต่างๆ ผลลัพธ์ของ Optimizer ไม่ใช่แค่บทสรุปข้อความ แต่เป็น Decision Tree (แผนภาพการตัดสินใจ) ที่ครอบคลุมทุกประเด็น ซึ่งช่วยชี้ให้เห็นอย่างชัดเจนว่าระบบกำลังมีช่องโหว่ทางตรรกะในจุดไหนบ้าง
- Targeted Evolution: สุดท้าย LLM "โค้ช" (Coach) จะรวม Decision Tree นี้เข้ากับ System Prompt โดยอาจจะเพิ่มเข้าไปเป็นแนวทางการคิด หรือเขียนคำสั่งใหม่ทั้งหมดเลยก็ได้ ก่อนจะส่งกลับไปทดสอบประสิทธิภาพ (Benchmarking) อีกครั้งเป็นวงจรไปเรื่อยๆ
ROAD เปลี่ยนการเขียน Prompt Engineering จากเดิมที่ต้องมานั่งสุ่มเดาด้วยตัวเอง ให้กลายเป็นกระบวนการอัตโนมัติที่มีระบบระเบียบในการดึงเอา 'รูปแบบความผิดพลาด' มาวิเคราะห์ ซึ่งการมุ่งเน้นไปที่จุดที่โมเดลทำงานพลาดนี้เอง ช่วยให้เราพัฒนาคำสั่ง (System Prompt) ที่แข็งแกร่งและรับมือกับความซับซ้อนของข้อมูลหน้างานจริงได้อย่างอยู่หมัด
ผลการดำเนินงาน
เพื่อตรวจสอบเวิร์กโฟลว์ ROAD เราได้ทดสอบวิธีนี้ในสองสภาพแวดล้อมที่แตกต่างกัน: การทดสอบมาตรฐานทางวิชาการ (τ2-bench) และระบบที่ใช้งานจริง (Accentix KM) ซึ่งผลลัพธ์จากทั้งสองกรณีชี้ให้เห็นว่า วงจรการวิเคราะห์ความผิดพลาดและการพัฒนา Decision Tree แบบอัตโนมัติ สามารถยกระดับประสิทธิภาพของระบบให้สูงขึ้นกว่าการใช้คำสั่งแบบพื้นฐานอย่างมีนัยสำคัญ
1. การทดสอบมาตรฐานทางวิชาการ: τ2-bench (โดเมนค้าปลีก)
ในขั้นแรก เราประเมินประสิทธิภาพของ ROAD ผ่านชุดทดสอบ ‘τ2-bench’ ซึ่งเป็นโครงสร้างการทดสอบที่เข้มงวดสำหรับการวัดผลระบบสนทนาอัตโนมัติในสภาพแวดล้อมแบบ 'การควบคุมคู่' (Dual-control) ที่ทั้งผู้ใช้และ AI ต่างมีอิสระในการโต้ตอบ โดยเรามุ่งเน้นไปที่กลุ่มธุรกิจค้าปลีก (Retail) ซึ่งเป็นงานที่ต้องใช้เครื่องมือซับซ้อน เช่น การแก้ไขคำสั่งซื้อ หรือการดำเนินการคืนเงิน
จากแผนภูมิจะเห็นได้ว่า เราได้ทดสอบเปรียบเทียบประสิทธิภาพในโมเดลต่างๆ รวมถึง o4-mini และ Qwen3-4B-Thinking-2507 โดยหากพิจารณาที่โมเดล Qwen3-4B-Thinking-2507 จะพบว่าในตอนเริ่มต้น (Baseline) ตัวแทนอัจฉริยะนี้มีคะแนนประสิทธิภาพอยู่ที่ประมาณ 53 คะแนน แต่หลังจากรันวงจร ROAD เพื่อคัดกรองความผิดพลาด วิเคราะห์สาเหตุต้นตอ และใส่ Decision Tree ที่ปรับปรุงแล้วกลับเข้าไปในคำสั่งระบบ ปรากฏว่าเราสามารถยกระดับประสิทธิภาพให้เพิ่มขึ้นได้อย่างชัดเจน
.png)
หลังจากการประยุกต์ใช้ ROAD คะแนนประสิทธิภาพของ Qwen3-4B-Thinking-2507 พุ่งสูงขึ้นไปอยู่ที่ประมาณ 63 คะแนน ซึ่งคิดเป็นการพัฒนาขึ้นถึง 19% ผลลัพธ์นี้เน้นย้ำถึงความสามารถของ Coach LLM ในการอุดช่องโหว่ทางตรรกะภายในกระบวนการคิดของเอเย่นต์ได้อย่างมีประสิทธิภาพ นอกจากนี้ โมเดล o4-mini ยังแสดงให้เห็นถึงการพัฒนาในทิศทางเดียวกัน โดยคะแนนเพิ่มขึ้นจากเดิมประมาณ 68 ไปเป็นเกือบ 78 คะแนน ซึ่งพิสูจน์ให้เห็นว่าเฟรมเวิร์กนี้ใช้งานได้ผลจริงแม้กระทั่งกับโมเดลระดับแนวหน้าที่แข็งแกร่งที่สุดในปัจจุบัน
ตัวอย่าง: การเติบโตของ System Prompt
เพื่อให้เห็นภาพประสิทธิภาพที่เพิ่มขึ้น 19% ของ Qwen3-4B-Thinking-2507 เราได้เปรียบเทียบคำสั่งพื้นฐาน กับ Decision Tree ที่ผ่านการปรับปรุงโดย ROAD หลังจากผ่านไป 6 การวนซ้ำ
ก่อนปรับปรุง: คำสั่งกำกวม (Baseline Prompt)
คำสั่งอยู่ในรูปแบบบทสนทนาและกำกวม เอเจนต์มักจะล้มเหลวในจุดนี้ เนื่องจากไม่ทราบลำดับขั้นตอนที่แน่ชัดในการจัดการกับงานที่ซับซ้อน
.png)
หลังปรับปรุง: Decision Tree ที่เข้มงวด (การวนซ้ำครั้งที่ 6)
ตัว Coach LLM ได้ใส่ 'โครงสร้างการทำงานแบบเรียงลำดับ' เข้าไปในคำสั่ง โดยมีการวางตรรกะอย่างชัดเจนเป็นลำดับขั้นตอน (เช่น ต้องตรวจสอบที่อยู่ก่อน แล้วค่อยดูรายการสินค้า) รวมถึงมีการบังคับให้ตรวจสอบความปลอดภัยด้วยคำว่า 'YES' อย่างชัดเจน
.png)
ไฮไลท์สำคัญในตัวอย่างนี้:
- การขจัดความกำกวม: "ยืนยันตัวตนผู้ใช้" (ก่อน) กลายเป็นเวิร์กโฟลว์ทีละขั้นตอน 1.1 / 1.2 / 1.3 ที่ชัดเจน
- การใส่ตรรกะ: ก่อนหน้านี้เอเจนต์ไม่รู้ว่าควรจะอัปเดตสิ่งใดก่อน (ที่อยู่หรือสินค้า) Prompt ใหม่บังคับใช้ลำดับขั้นตอน (5B.5) เพื่อป้องกันข้อผิดพลาดในฐานข้อมูล
- เกราะป้องกันความปลอดภัย: การ "ขอคำยืนยัน" แบบทั่วไป กลายเป็นข้อกำหนดที่ต้องพิมพ์คำว่า "YES" เท่านั้น เพื่อลดการทำงานโดยไม่ตั้งใจ
2. การประยุกต์ใช้งานในโลกจริง: Accentix KM Engine
แม้ว่าการทดสอบทางวิชาการจะเป็นสนามทดสอบที่มีการควบคุม แต่การตรวจสอบคุณค่าที่แท้จริงของ ROAD คือต้องนำไปใช้งานจริงในระบบที่เปิดให้บริการอยู่ เราจึงได้นำเวิร์กโฟลว์นี้ไปใช้กับ Accentix Knowledge Management (KM) ซึ่งเป็นระบบที่มีหน้าที่ค้นหาเอกสารและตอบคำถามยากๆ ของลูกค้าให้ถูกต้องแม่นยำที่สุด
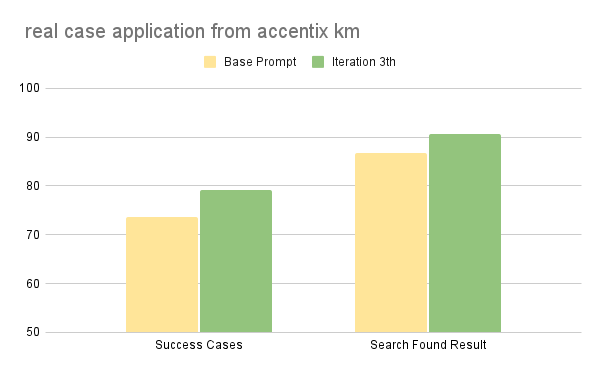
สิ่งที่ต่างจากชุดทดสอบทางวิชาการที่ต้องปรับปรุงถึง 6 รอบกว่าจะลงตัว คือการใช้งานในโลกจริงของเราเห็นผลลัพธ์ที่คงที่อย่างรวดเร็ว ดังที่แสดงในแผนภูมิด้านล่าง ที่เพียงแค่ผ่านไป 3 รอบการวนซ้ำ เราก็สามารถสร้างการพัฒนาที่วัดผลได้จริงในทุกตัวชี้วัดหลัก (KPIs) ของเรา
- Success Cases (73.6% → 79.2%): อัตราความสำเร็จของงานโดยรวมเพิ่มขึ้น 5.6% แสดงให้เห็นว่า Decision Tree ที่สร้างโดย Optimizer สามารถแก้กำกวมของเจตนาผู้ใช้ (User Intents) ที่เคยทำให้บทสนทนาไปต่อไม่ได้
- Search Found Result (86.8% → 90.6%): ประเด็นสำคัญคือ ความสามารถในการค้นหาผลลัพธ์ที่ถูกต้องเพิ่มขึ้น 3.8% สิ่งนี้ชี้ให้เห็นว่าการวิเคราะห์ความล้มเหลวของเราสามารถวินิจฉัยแพทเทิร์นการค้นหาที่ไม่ได้ประสิทธิภาพได้สำเร็จ (เช่น การใช้คีย์เวิร์ดที่เฉพาะเจาะจงเกินไป) ทำให้โค้ชสามารถอัปเดต Prompt ด้วยกลยุทธ์การค้นหาที่ครอบคลุมและทนทานกว่าเดิม
การปรับปรุงที่เกิดขึ้นอย่างรวดเร็วนี้ยืนยันว่า ROAD สามารถปรับตัวเข้ากับกรณีปัญหาพิเศษ (Edge cases) ที่มีความซับซ้อนและไร้ระเบียบซึ่งมักพบในข้อมูลการใช้งานจริงได้อย่างมีประสิทธิภาพ พร้อมทั้งช่วยอุดช่องโหว่ทางตรรกะที่ชุดทดสอบมาตรฐานทั่วไปอาจมองข้ามไป
กรณีศึกษา 1: การปรับแต่งคำค้นหาตามบริบท (Contextual Query Reformulation)
ความท้าทาย: ผู้ใช้ให้ข้อมูลผ่านการสนทนาหลายรอบ โดยโมเดล "ก่อนปรับปรุง" ไม่สามารถดึงบริบทจากคำถามแรก ("ทุพพลภาพ") มายังคำถามที่สอง ("โรงพยาบาลเอกชน") ได้ ส่งผลให้มันค้นหาเพียงคำกว้างๆ ของคำว่า "เอกชน"
- ครั้งที่ 1 บริบทการสนทนา: "ค่ารักษาพยาบาลผู้ป่วยนอกสำหรับกรณีทุพพลภาพอยู่ที่เท่าไหร่?"
- ครั้งที่ 2 ข้อมูลนำเข้า: "โรงพยาบาลเอกชน"

กรณีศึกษา 2: การป้องกันการหลอนข้อมูลและการจัดการขอบเขต (Hallucination Prevention)
ความท้าทาย: ผู้ใช้ถามคำถามเชิงคาดการณ์และความเห็นเกี่ยวกับอนาคตของกองทุนประกันสังคม ("เงินจะหมดใน 20 ปีไหม?") โดยโมเดล "ก่อนปรับปรุง" พยายามตอบด้วยข้อมูลทั่วไป ในขณะที่โมเดล "หลังปรับปรุง" ระบุได้อย่างถูกต้องว่านี่อยู่นอกขอบเขตข้อมูล
- คำถาม: "ได้ยินข่าวมาว่าถ้าไม่มีคนใหม่ๆ จ่ายเงินสมทบ กองทุนประกันสังคมจะเงินหมด... แล้วตอนผมอายุ 60 ผมยังจะได้เงินอยู่ไหมครับ?"
.png)
บทสรุป
ในสนามแข่งที่ต้องเข็นระบบออกมาใช้งานให้ไวที่สุด ความเร็วไม่ใช่แค่ตัวเลขชี้วัด แต่มันคือการอยู่รอด การเปลี่ยนผ่านสู่เวิร์กโฟลว์ ROAD พิสูจน์ให้เห็นว่าเราไม่ต้องเลือกระหว่าง "การติดตั้งที่รวดเร็ว" กับ "การติดตั้งที่ชาญฉลาด" อีกต่อไป เพราะเราสามารถทำทั้งสองอย่างไปพร้อมกันได้
ในขณะที่อัลกอริทึม GEPA ดั้งเดิมปฏิวัติวงการวิชาการด้วยการลดความต้องการตัวอย่างข้อมูลลงมหาศาลเมื่อเทียบกับ RL แบบดั้งเดิม แต่ ROAD ได้ก้าวไปอีกขั้นด้วย Zero-Shot Data Curation (การคัดกรองข้อมูลโดยไม่ต้องใช้มนุษย์เตรียม) เราบรรลุความสำเร็จที่เพิ่มขึ้น 5.6% และความแม่นยำในการค้นหาเพิ่มขึ้น 3.8% ไม่ใช่โดยการใช้เวลาหลายสัปดาห์เพื่อคัดแยกข้อมูลเอง (Labeling Data) แต่เพียงแค่ปล่อยให้ระบบเรียนรู้จากความผิดพลาดของตัวเอง
ด้วยการทำงานแบบอัตโนมัติเพียงสามรอบการวนซ้ำ ROAD สามารถยกระดับประสิทธิภาพได้เทียบเท่ามาตรฐานการใช้งานจริง (Production-grade) โดยไม่ต้องใช้แรงงานคนเข้ามาแทรกแซงเลยแม้แต่น้อย
การแลก Token กับเวลา: ROI สูงสุด
นักวิจารณ์อาจชี้ให้เห็นถึงสิ่งที่เรียกว่า 'ภาษีโทเค็น' (Token Tax) หรือต้นทุนการประมวลผลที่สูงขึ้นจากการใช้ LLM ถึงสามตัวแยกกันเพื่อทำหน้าที่วิเคราะห์ ปรับปรุง และเป็นโค้ช แต่สำหรับเรา สิ่งนี้ไม่ใช่ต้นทุนที่สูญเปล่า แต่คือ 'การลงทุนที่คุ้มค่า' (Strategic Leverage)
เรากำลังแลกเครดิตการประมวลผลราคาถูก กับชั่วโมงการทำงานอันมีค่าของวิศวกร แทนที่จะต้องให้หัวหน้าวิศวกรมาเสียเวลาวิเคราะห์ Log และปรับแต่ง Prompt ด้วยตัวเอง ROAD จะทำหน้าที่หนักเหล่านั้นให้โดยอัตโนมัติ และระบุช่องว่างทางตรรกะและแก้ไขข้อผิดพลาดที่ "ไม่น่าเกิด" ได้ในเวลาไม่กี่ชั่วโมง แทนที่จะเป็นหลายวัน นี่ไม่ใช่ค่าใช้จ่าย แต่เป็นการลงทุนในเรื่องของความเร็ว
สุดท้ายนี้
ROAD คือตัวเร่งประสิทธิภาพสูงสุดสำหรับการแก้ปัญหา 'Cold Start' (การเริ่มต้นจากศูนย์) เป็นสะพานที่เปลี่ยนโปรโตไทป์อันยุ่งเหยิงไปสู่เอเจนต์ที่แข็งแกร่งและแก้ไขตัวเองได้ แม้อาจจะไม่ไปถึงจุดสูงสุดในทางทฤษฎีเท่ากับการฝึก RL ที่ต้องรันข้อมูลมหาศาลถึง 20,000 ครั้ง แต่ ROAD สามารถแก้ปัญหาที่สำคัญจริงๆ ต่อธุรกิจได้ นั่นคือ การนำเอเจนต์คุณภาพสูงเข้าสู่การใช้งานจริงให้ได้ทันที
หมดยุคสมัยของการนั่งปรับแต่ง Prompt ด้วยตัวเองแล้ว ด้วย ROAD เราไม่ได้แค่สร้างเอเจนต์ แต่เรากำลังสร้างระบบที่สามารถเรียนรู้และอัปเกรดตัวเองได้โดยอัตโนมัติ
สนใจร่วมเป็นส่วนหนึ่งกับ AI Labs ของเราได้ที่นี่