
Boosting Text-to-SQL Accuracy 7× with GEPA
Introduction
Modern generative models have made it easier than ever to turn human language into actionable queries. Yet building a reliable text‑to‑SQL system for enterprise analytics remains challenging. Natural language questions may blend Thai and English, contain jargon, or imply complex filtering and grouping. Drafting the right system prompt—one that instructs an LLM to generate valid SQL for a particular schema—is a time‑consuming art. Our team recently built a text‑to‑SQL agent using DSPy and discovered that prompt quality alone can make or break performance. A simple baseline prompt achieved only 5.7 % accuracy, highlighting how brittle manual prompt engineering can be. To address this bottleneck we turned to GEPA (Genetic Evolutionary Prompt Optimization), a technique for automatically improving prompts.
Understanding GEPA: Genetic Evolutionary Prompt Optimization
GEPA is a prompt‑optimization algorithm originally developed by researchers at Databricks and UC Berkeley. Instead of manually tweaking instructions, GEPA treats the prompt itself as a “program” and applies evolutionary search guided by feedback. The optimizer model (which can be a stronger LLM) generates candidate instructions, evaluates them on a task, and iteratively refines the best candidates using reflection and mutation. Databricks researchers describe GEPA as a new prompt optimizer that combines language‑based reflection with evolutionary search to improve AI systems. In their experiments, GEPA was compared with Bayesian (MIPRO) and stochastic (SIMBA) search methods and consistently delivered the largest quality gains.
Crucially, GEPA not only improves accuracy but also shifts the quality–cost Pareto frontier. Databricks showed that applying GEPA to the open‑source model gpt‑oss‑120b allowed it to surpass proprietary models like Claude Sonnet 4 and Claude Opus 4.1 while being roughly 22× and 90× cheaper to serve. They also demonstrated that prompt optimization can match or exceed the gains from supervised fine‑tuning (SFT) while reducing serving cost by about 20 %, and combining GEPA with SFT yields even higher performance (Databricks, 2025). These findings inspired us to apply GEPA to our text‑to‑SQL agent.
Challenges and Baseline Performance
Translating natural‑language questions into SQL is particularly demanding. The agent must understand the user’s intent, map colloquial phrases to table and column names, and ensure that the resulting query respects join relationships and schema constraints. Our dataset comprises Thai and English questions with a variety of aggregations, date filters and grouping tasks. We built an initial DSPy program with a straightforward instruction: "Given a question, generate the SQL query." We evaluated this baseline program on our test set using a compare_dbx metric that normalizes and compares the generated SQL to the gold answer. The result was sobering—accuracy barely reached 5.7 %. This confirmed that a naïve prompt fails to capture the nuances of our schema and query patterns.
To visualize the improvement journey, the figure below shows our baseline accuracy compared to the optimized result (described next).
.png)
Applying GEPA to Optimize Our Text‑to‑SQL Pipeline
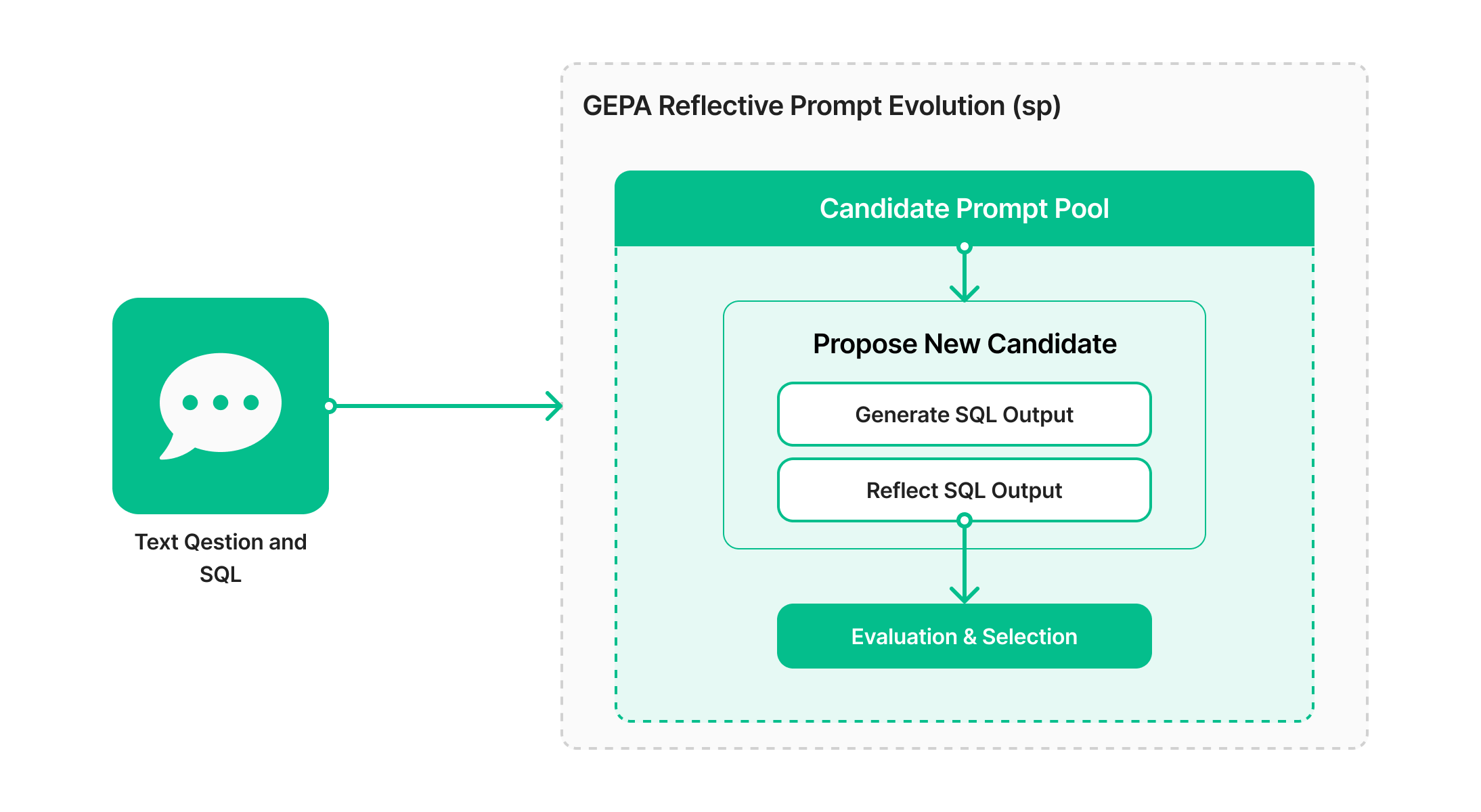
We integrated GEPA via the dspy library’s GEPA optimizer. Our pipeline first defines a program that maps question -> sql and uses dspy.Evaluate with our SQL comparison metric to compute a numeric score. We then invoked GEPA to search over variations of the instruction component of the prompt. GEPA’s evolutionary search gradually mutates the instruction, using our evaluation feedback to select higher‑scoring prompts. Unlike SIMBA or MIPRO (which search through few‑shot examples and instructions), we focused on optimizing the instruction because our dataset’s language diversity made few‑shot selection tricky.
The results were striking. After running GEPA for a few hours, the optimized instruction produced 41.3 % accuracy on the same test set—an improvement of over 7× relative to the baseline. The optimized prompt contained detailed instructions about the schema, encouraged the model to reason step by step, and specified the expected SQL ordering and grouping. This experience mirrors Databricks’ observation that GEPA can raise the performance of an open‑source model beyond closed‑source baselines while automatically discovering better prompts.
Conclusion
Our foray into automated prompt optimization transformed a struggling text‑to‑SQL agent into a competent system with over 41 % accuracy, simply by letting an optimizer refine the prompt. GEPA demonstrated that evolutionary search and language‑based reflection can systematically outperform manual trial‑and‑error. Beyond our use case, research from Databricks shows that GEPA can elevate open‑source models above closed‑source rivals and dramatically reduce inference cost. As large language models become ubiquitous in enterprise pipelines, tools like GEPA will be indispensable for delivering high‑quality, cost‑efficient AI agents.
Collaborate and partner with our AI Lab at Amity here
