

เพิ่มความแม่นยำ Text-to-SQL 7 เท่าด้วย GEPA
บทนำ
ปัจจุบัน AI ช่วยให้เราสามารถแปลงภาษามนุษย์ให้กลายเป็นคำสั่งที่คอมพิวเตอร์เข้าใจได้ง่ายขึ้นกว่าที่เคยเป็นมา อย่างไรก็ตาม การสร้างระบบ text-to-SQL ที่สามารถแปลงคำถามจากภาษามนุษย์ให้เป็นคำสั่ง SQL สำหรับงานวิเคราะห์ข้อมูลในองค์กรยังคงมีความท้าทาย เนื่องจากคำถามที่ผู้ใช้พิมพ์เข้ามาอาจมีทั้งภาษาไทยและอังกฤษปนกัน หรืออาจใช้ศัพท์เฉพาะทางธุรกิจ หรือมีเงื่อนไขซับซ้อนหลายชั้น ซึ่งการเขียน system prompt ที่บอกให้โมเดลสร้าง SQL ที่ถูกต้องตามโครงสร้างของฐานข้อมูล จึงเป็นงานที่ต้องใช้เวลาและความละเอียดสูง โดยเราได้ทดลองสร้าง text-to-SQL agent โดยใช้ DSPy framework พบว่า “คุณภาพของ prompt” เพียงอย่างเดียวสามารถส่งผลอย่างมากต่อประสิทธิภาพของโมเดล จากการทดสอบ baseline เราได้ความแม่นยำเพียง 5.7% เท่านั้น ซึ่งแสดงให้เห็นว่าการเขียน prompt แบบ Manual ยังมีข้อจำกัดและผิดพลาดได้ง่าย เพื่อแก้ปัญหานี้ เราได้นำเทคนิค GEPA (Genetic Evolutionary Prompt Optimization) เข้ามาช่วย — เครื่องมือที่สามารถ “ปรับปรุง prompt แบบอัตโนมัติ” ด้วยอัลกอริทึมเชิงวิวัฒนาการ (evolutionary Prompt)
ทำความเข้าใจกับ GEPA: Genetic Evolutionary Prompt Optimization
GEPA คืออัลกอริทึมสำหรับปรับปรุง prompt ที่ถูกพัฒนาโดยทีมวิจัยจาก Databricks และ มหาวิทยาลัย UC Berkeley โดยแทนที่จะปรับคำสั่งด้วยมือ GEPA มองว่า “prompt” คือโปรแกรมที่สามารถพัฒนาได้ และใช้กระบวนการค้นหาเชิงวิวัฒนาการ (evolutionary search) ที่ขับเคลื่อนด้วย feedback เพื่อหาคำสั่งที่ให้ผลดีที่สุด โดย Optimizer จะสร้าง Prompt ใหม่หลายแบบ และประเมินผลลัพธ์ในแต่ละรอบ จากนั้นนำมาปรับต่อผ่านกระบวนการ “reflection” เพื่อวิเคราะห์ผลลัพธ์จากรอบก่อนหน้า ว่าทำไม prompt นั้นถึงได้คะแนนต่ำ หรือคำสั่ง SQL ที่สร้างออกมาผิดพลาดตรงไหน ผลจากการ reflection นี้จะถูกใช้เป็น “คำแนะนำ” เพื่อปรับปรุง prompt ในรอบถัดไป และเข้าสู่ “mutation” คือการ “ปรับแต่ง” ตัว prompt ตามข้อเสนอแนะที่ได้จาก reflection จากนั้นจะทำซ้ำไปเรื่อย ๆ แล้วคัดเลือก prompt ที่ให้คะแนนดีที่สุด
นักวิจัยจาก Databricks อธิบายว่า GEPA เป็นตัว “ปรับ prompt อัจฉริยะ” ที่ผสานสองแนวคิดหลักคือ
- Language-based reflection: การวิเคราะห์และสะท้อนผลด้วยภาษา
- Evolutionary search: การค้นหาและปรับปรุง prompt แบบวิวัฒนาการ
จากผลการทดลอง GEPA ให้ประสิทธิภาพเหนือกว่าวิธีอื่น เช่น MIPRO (Bayesian) และ SIMBA (Stochastic) โดยเพิ่มคุณภาพของผลลัพธ์ได้อย่างต่อเนื่อง ที่สำคัญ GEPA ไม่ได้แค่เพิ่มความแม่นยำ แต่ยังช่วยพัฒนาความสมดุลระหว่างคุณภาพกับต้นทุน (Quality–Cost Pareto Frontier) ได้อีกด้วย
ทีม Databricks พบว่า เมื่อใช้ GEPA กับโมเดล open source gpt-oss-120b ผลลัพธ์กลับเหนือกว่าโมเดล closed-source อย่าง Claude Sonnet 4 และ Claude Opus 4.1 ในขณะที่ต้นทุนต่ำกว่าถึง 22 เท่า และ 90 เท่า ตามลำดับ นอกจากนี้ยังพบว่า การปรับ prompt ด้วย GEPA ให้ผลลัพธ์ใกล้เคียงหรือดีกว่าการทำ Supervised Fine-Tuning (SFT) แต่ลดต้นทุนรันได้ราว 20% และเมื่อใช้ GEPA ร่วมกับ SFT ผลลัพธ์จะดียิ่งขึ้นอีก
ซึ่งผลการวิจัยเหล่านี้ทำให้เราอยากนำ GEPA มาปรับใช้กับระบบ text-to-SQL ของเราด้วยเช่นกัน
ความท้าทายและผลลัพธ์เริ่มต้น
การแปลงคำถามภาษามนุษย์ให้กลายเป็นคำสั่ง SQL เป็นงานที่ซับซ้อน เพราะระบบต้องเข้าใจเจตนาของผู้ใช้ แปลงถ้อยคำทั่วไปให้ตรงกับชื่อคอลัมน์และตาราง และยังต้องสร้างคำสั่งที่สอดคล้องกับโครงสร้างและข้อจำกัดของฐานข้อมูล ชุดข้อมูลของเราประกอบด้วยคำถามทั้งภาษาไทยและอังกฤษ รวมถึงโจทย์ที่มีการคำนวณแบบรวมกลุ่ม (aggregation) การกรองข้อมูลตามวันที่ และการจัดกลุ่มข้อมูลหลายรูปแบบ โดยเราเริ่มจากการสร้างโปรแกรมพื้นฐานใน DSPy โดยใช้คำสั่งง่าย ๆ ว่า
“เมื่อได้รับคำถาม ให้สร้างคำสั่ง SQL ที่ตรงกับคำถามนั้น”
จากนั้นทดสอบด้วยเมตริก compare_dbx ซึ่งจะทำหน้าที่ normalize และเปรียบเทียบ SQL ที่ได้กับคำตอบจริง (gold answer) ผลลัพธ์คือความแม่นยำเพียง 5.7% ซึ่งยืนยันว่าการใช้ prompt พื้นฐานยังไม่สามารถรองรับความซับซ้อนของ schema และรูปแบบคำถามได้ดีพอ กราฟด้านล่างแสดงการเปรียบเทียบความแม่นยำของโมเดลเริ่มต้นกับผลลัพธ์หลังการปรับให้เหมาะสม (ซึ่งอธิบายไว้ในส่วนถัดไป)
.png)
การใช้ GEPA เพื่อปรับปรุงระบบ Text-to-SQL
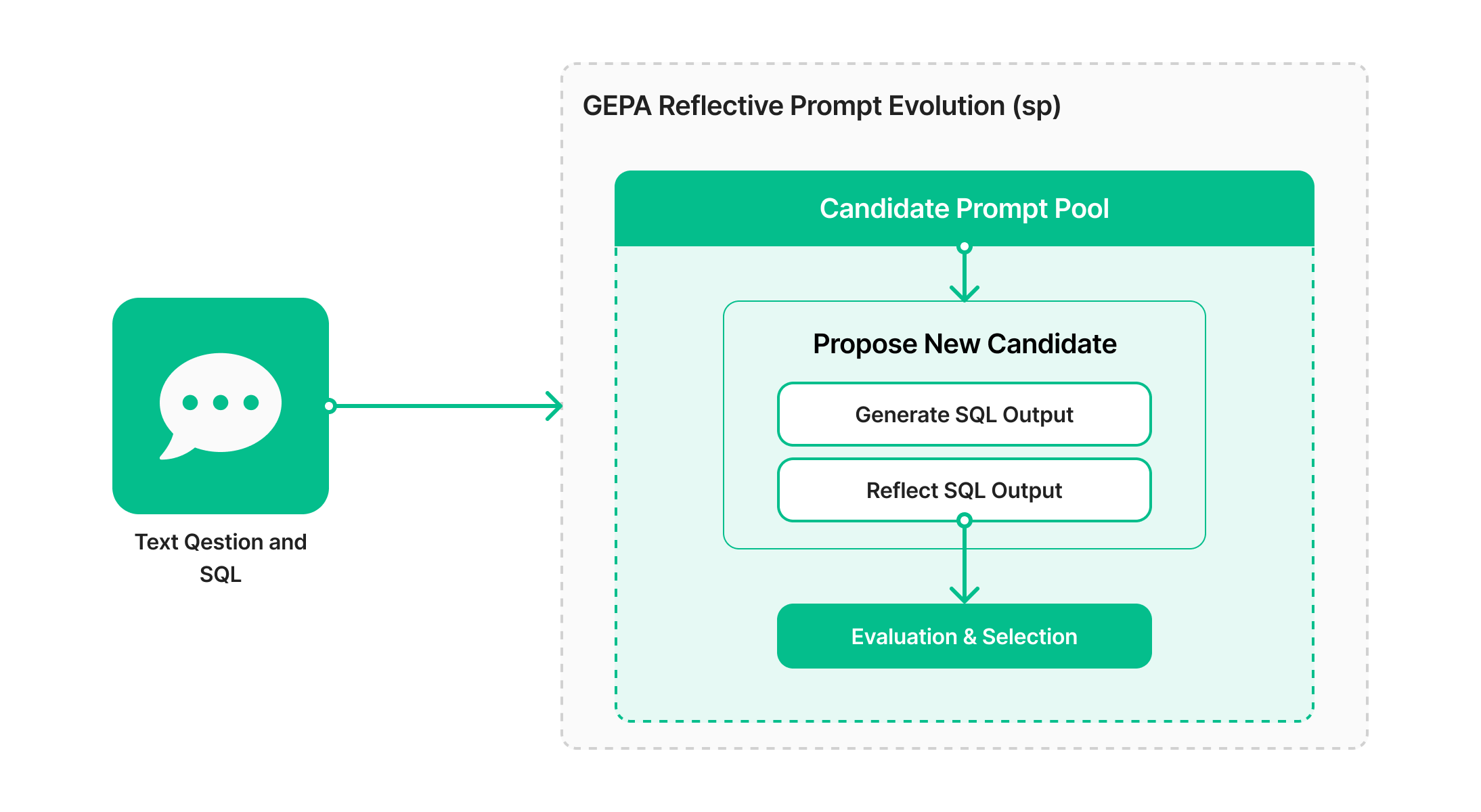
เราได้นำ GEPA มาผสานเข้ากับระบบผ่าน GEPA optimizer ของไลบรารี DSPy เพื่อเพิ่มประสิทธิภาพให้กับกระบวนการสร้างคำสั่ง SQL จากภาษาธรรมชาติ
ขั้นแรก เรากำหนดโปรแกรมที่แปลง คำถาม (question) ให้กลายเป็น คำสั่ง SQL จากนั้นใช้ฟังก์ชัน dspy.Evaluate ร่วมกับตัวชี้วัดการเปรียบเทียบ SQL ของเรา เพื่อคำนวณคะแนนความถูกต้องเชิงตัวเลข
จากนั้น เราเรียกใช้งาน GEPA เพื่อค้นหาการปรับแต่งในส่วนของ instruction ภายใน prompt โดยกระบวนการค้นหาของ GEPA จะค่อย ๆ ปรับเปลี่ยน (mutate) คำสั่งเหล่านี้ตามผลลัพธ์การประเมิน เพื่อคัดเลือก prompt ที่ให้คะแนนดีที่สุดในแต่ละรอบ การทำงานลักษณะนี้ช่วยให้ GEPA “เรียนรู้จากผลลัพธ์” และปรับปรุงตัวเองอย่างต่อเนื่อง ต่างจากวิธีอย่าง SIMBA หรือ MIPRO ซึ่งค้นหาทั้งตัวอย่าง few-shot และคำสั่งพร้อมกัน เราเลือกมุ่งเน้นไปที่การปรับเฉพาะ instruction เท่านั้น เพราะข้อมูลของเรามีความหลากหลายด้านภาษา ทำให้การเลือก few-shot ตัวอย่างค่อนข้างซับซ้อน
ผลลัพธ์ที่ได้ถือว่าน่าประทับใจ — หลังจากให้ GEPA ทำงานเพียงไม่กี่ชั่วโมง คำสั่งที่ผ่านการปรับแต่งแล้วสามารถทำความแม่นยำได้ถึง 41.3% บนชุดทดสอบเดียวกัน เพิ่มขึ้นมากกว่า 7 เท่า เมื่อเทียบกับค่าพื้นฐานเดิม
Prompt ที่ได้จาก GEPA มีคำแนะนำชัดเจนขึ้น เช่น
- อธิบาย schema ของฐานข้อมูลอย่างครบถ้วน
- แนะนำให้โมเดล “คิดทีละขั้นตอน” (step-by-step reasoning)
- กำหนดรูปแบบ SQL เช่น การเรียงลำดับและการจัดกลุ่มข้อมูลอย่างชัดเจน
ผลลัพธ์นี้สอดคล้องกับสิ่งที่ Databricks รายงานไว้ว่า GEPA สามารถยกระดับประสิทธิภาพของโมเดล open-source ให้เหนือกว่าโมเดล close-source ได้จริง และยังค้นพบ prompt ที่ดีกว่าอย่างอัตโนมัติ
สรุป
การนำระบบปรับ prompt อัตโนมัติมาใช้ เปลี่ยน text-to-SQL agent ของเราให้กลายเป็นระบบที่ทำงานได้อย่างมีประสิทธิภาพมากขึ้น เพียงแค่ให้ตัว optimizer ปรับ prompt ด้วยตัวเอง ความแม่นยำก็เพิ่มขึ้นถึงกว่า 41%
GEPA แสดงให้เห็นว่า การผสานเทคนิค evolutionary search และ language-based reflection สามารถให้ผลดีกว่าการลองผิดลองถูกแบบ manual นอกจากนี้ งานวิจัยจาก Databricks ยังยืนยันว่า GEPA สามารถทำให้โมเดลแบบ open-source มีประสิทธิภาพเหนือกว่าโมเดล close-source ที่มีราคาแพงกว่า ซึ่งสามารถลดต้นทุนการประมวลผลลงได้อย่างมาก
เมื่อ LLM ถูกนำมาใช้ในองค์กรอย่างแพร่หลาย เครื่องมืออย่าง GEPA จะกลายเป็นกุญแจสำคัญในการสร้าง AI Agent ที่แม่นยำ คุ้มค่า และพร้อมใช้งานจริงในระดับองค์กร
สนใจร่วมเป็นส่วนหนึ่งกับ Amity AI Labs ของเราได้ที่นี่