

TRAG Leaderboard
ภาพรวมของ TRAG
Thai Retrieval Augmented Generation (TRAG) เป็นเกณฑ์มาตรฐานที่ถูกพัฒนาขึ้นเพื่อประเมินประสิทธิภาพของโมเดลภาษาขนาดใหญ่ (Large Language Models: LLMs) ในด้านความสามารถในการทำความเข้าใจและการสร้างคำตอบที่เป็นธรรมชาติในภาษาไทย ต่อจากนี้จะเป็นการอธิบายรายละเอียดเกี่ยวกับโครงสร้างของเกณฑ์มาตรฐาน เกณฑ์การประเมิน และวิธีการให้คะแนน
โครงสร้างเกณฑ์มาตรฐาน
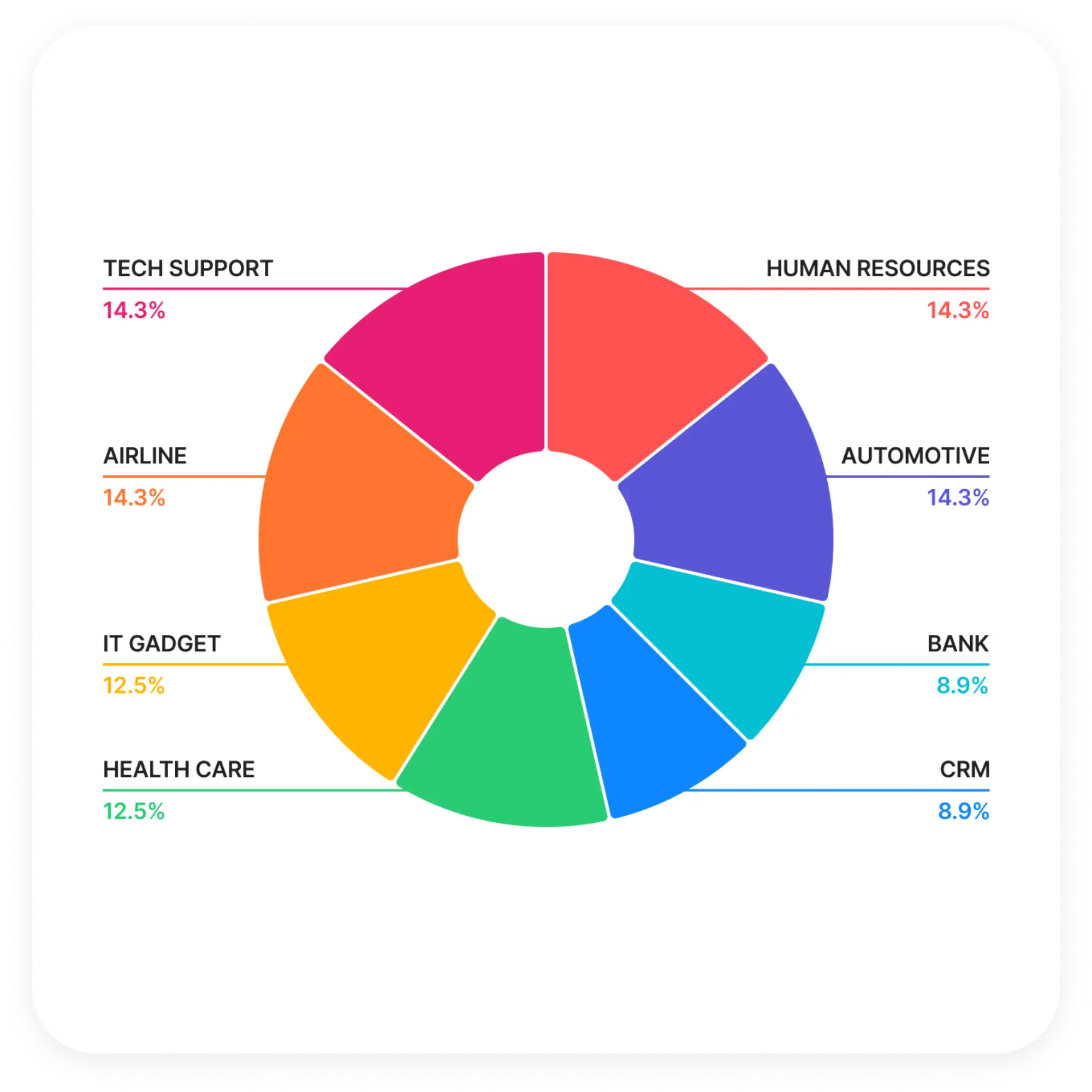
TRAG Benchmark ประกอบด้วยชุดทดสอบ 56 กรณี แบ่งเป็น 8 หมวดหมู่ และ 7 สถานการณ์ที่แตกต่างกันแต่ละกรณีทดสอบประกอบด้วยคำถามของผู้ใช้และเอกสารบริบทที่เกี่ยวข้อง โดยมีการกระจายตัวของชุดทดสอบดังนี้
หมวดหมู่
- สายการบิน – นโยบายและขั้นตอนต่างๆ ของสายการบิน เช่น การจองที่นั่ง การกำหนดราคาตั๋ว กำหนดเวลาสิ้นสุดโปรโมชัน
- ยานยนต์ – ความรู้เกี่ยวกับยานยนต์ เช่น อุปกรณ์เสริมรถยนต์ ความสามารถในการรับน้ำหนัก โปรโมชันปัจจุบัน
- ธนาคาร – ความรู้ด้านธนาคาร เช่น เอกสารที่จำเป็นสำหรับการปิดบัญชีหรือการมอบอำนาจ ขั้นตอนการปิดบัญชีออมทรัพย์และการเปิดบัญชีใหม่
- การบริหารลูกค้าสัมพันธ์ – ความรู้เกี่ยวกับสมาชิก เช่น วิธีการสมัคร การตรวจสอบคะแนน การใช้คะแนน และการคำนวณคะแนนสะสม
- การดูแลสุขภาพ – ความรู้ทางการแพทย์ เช่น การดูแลทันตกรรมสำหรับผู้ป่วย และยารักษาโรคความดันโลหิตสูง
- ทรัพยากรบุคคล – สวัสดิการด้านการรักษาพยาบาลของพนักงาน รวมถึงความคุ้มครองประกัน นโยบายการเบิกจ่าย และรายชื่อสถานพยาบาลที่กำหนด
- อุปกรณ์ไอที – คำถามจากผู้ใช้ รวมถึงโทรศัพท์มือถือที่มีกล้องคุณภาพดี และการเปรียบเทียบระหว่างสมาร์ทโฟน
- การสนับสนุนด้านเทคนิค – การตั้งค่า LAN การกู้คืนรหัสผ่าน และการตั้งค่าเราเตอร์ WiFi
สถานการณ์ทดสอบ
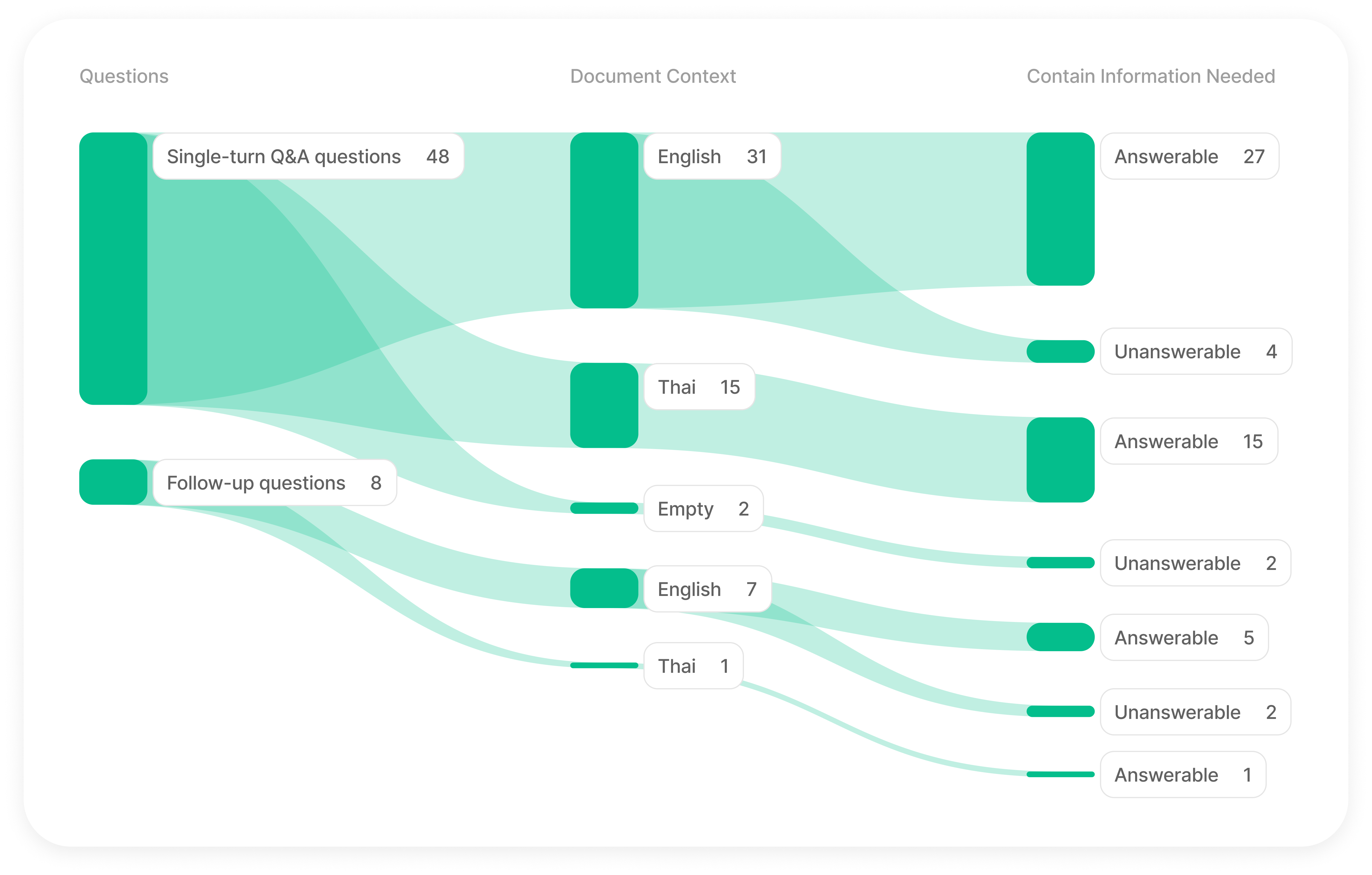
TRAG Benchmark ประกอบด้วย 7 สถานการณ์ที่แตกต่างกัน โดยพิจารณาจากปัจจัยสำคัญ 3 ประกา
- 1. ประเภทของคำถาม: การถาม-ตอบแบบครั้งเดียว: คำถามพื้นฐานที่สามารถตอบได้ในครั้งเดียว, คำถามต่อเนื่อง: คำถามเชิงลึกที่มีประวัติการสนทนาประกอบ
- 2. ภาษาของเอกสารบริบท:
ภาษาอังกฤษ
ภาษาไทย
ไม่มีเอกสารบริบท (โดยเจตนา) - 3. ความพร้อมของข้อมูล:
มีข้อมูลพร้อม: มีข้อมูลที่จำเป็นสำหรับการสร้างคำตอบ
ไม่มีข้อมูลพร้อม: ไม่มีข้อมูลที่จำเป็น แต่คำตอบควรสอดคล้องกับโจทย์ที่กำหนด
เกณฑ์การประเมิน
TRAG Benchmark ประเมินประสิทธิภาพของ LLMs ในหลายมิติที่สำคัญ:
ความถูกต้องของข้อเท็จจริง
คำตอบที่สร้างขึ้นต้องมีความสอดคล้องกับข้อเท็จจริงที่ปรากฏในเอกสารบริบท หากไม่พบข้อมูลที่ต้องการในบริบทที่กำหนด โมเดลจะต้องตอบว่า "ขออภัยค่ะ ไม่พบข้อมูล"
คุณภาพของภาษา
- คำตอบต้องเป็นภาษาไทยที่ปราศจากข้อผิดพลาดด้านไวยากรณ์ การสะกดคำ หรือการใช้คำ
- ต้องใช้น้ำเสียงที่สุภาพและเป็นทางการ โดยลงท้ายประโยคด้วย "ค่ะ"
- ต้องมีโครงสร้างประโยคที่ถูกต้องและการเรียบเรียงคำตอบที่สมบูรณ์
รูปแบบ
คำตอบต้องอยู่ในรูปแบบข้อความธรรมดา โดยไม่มีการจัดรูปแบบพิเศษหรือมาร์กดาวน์
ความเร็วในการตอบสนอง
โมเดลต้องสร้างคำตอบภายในระยะเวลาที่กำหนด คือ 15 วินาที.
TRAG Benchmark ใช้กระบวนการให้คะแนนสองขั้นตอน:
- 1. การให้คะแนนโดยรวมด้วย LLM: gpt-4o-2024-05-13 ซึ่งเป็น LLM ขั้นสูง ทำหน้าที่เป็นผู้ประเมินที่เป็นกลางในการประเมินคุณภาพของคำตอบที่สร้างขึ้นโดยโมเดลที่ทดสอบ โดยประเมินแต่ละคำตอบตามเกณฑ์การประเมินที่กล่าวมาข้างต้น
- 2. การจำแนกความสามารถในการตอบคำถามด้วย LLM: gpt-4-0613 ใช้ LLM ในการจำแนกคำตอบที่เป็นการจินตนาการ (hallucination) เพื่อตรวจสอบว่า LLM ใช้เฉพาะข้อมูลจากเอกสารที่กำหนดให้ในการตอบคำถามผู้ใช้หรือไม่
ผลการทดสอบเกณฑ์มาตรฐาน
TRAG Benchmark แสดงผลการทดสอบประสิทธิภาพของ LLMs ต่างๆ ในรูปแบบตารางจัดอันดับ ตารางจัดอันดับนี้จะได้รับการปรับปรุงอย่างสม่ำเสมอเมื่อมีการประเมินโมเดลใหม่

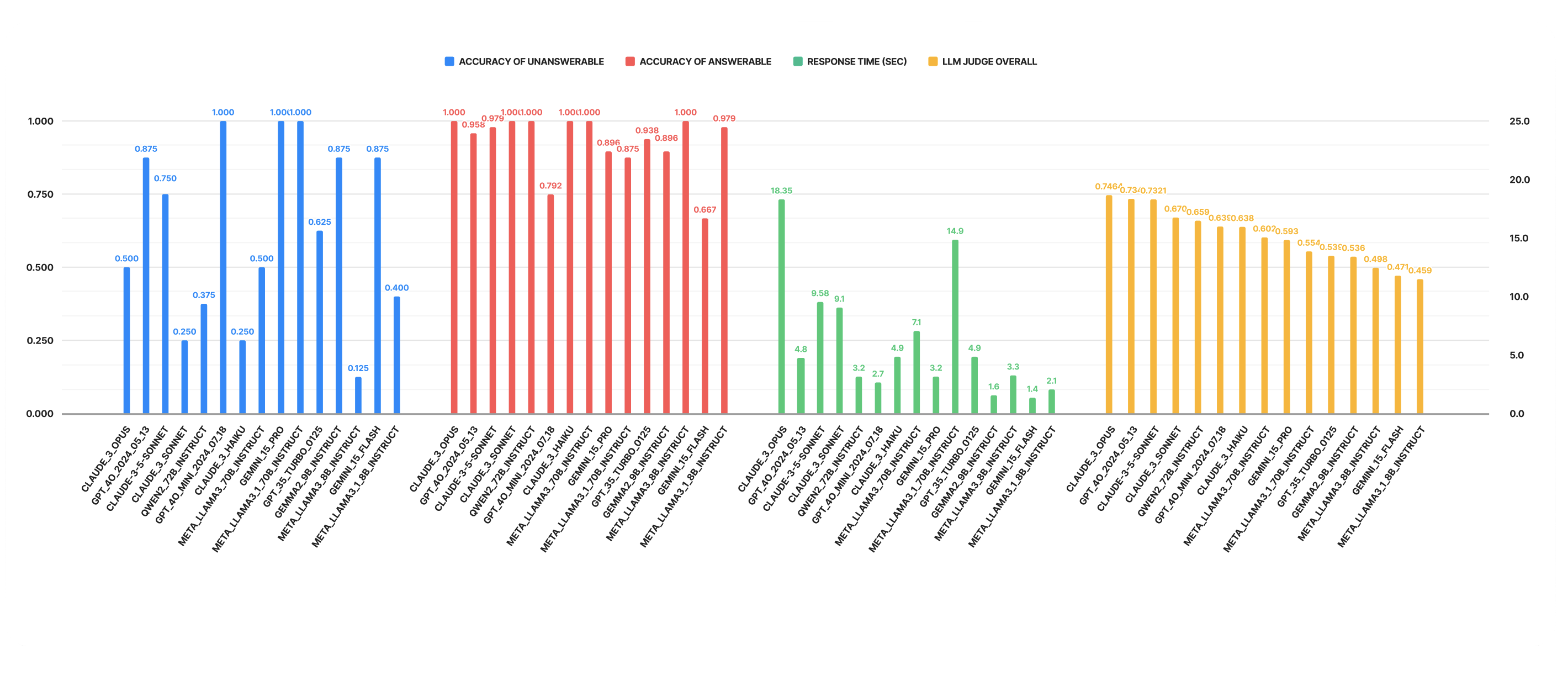
- คะแนนรวมจากการประเมินโดย LLM – ความแม่นยำโดยรวมของแต่ละโมเดลในการสร้างคำตอบ โดยพิจารณาปัจจัยต่างๆ เช่น ความถูกต้อง ไวยากรณ์ การแปล และข้อจำกัดเพิ่มเติม ซึ่งประเมินโดย GPT-4-2024-05-13
- ความแม่นยำในการตอบคำถามที่ไม่มีข้อมูล – ความสามารถของโมเดลในการตอบ "ไม่พบข้อมูล" อย่างถูกต้องเมื่อไม่มีข้อมูลที่จำเป็นในเอกสาร ซึ่งประเมินโดย GPT-4-0613
- ความแม่นยำในการตอบคำถามที่มีข้อมูล – ความสามารถของโมเดลในการให้คำตอบที่ถูกต้องเมื่อมีข้อมูลที่จำเป็นในเอกสาร ซึ่งประเมินโดย GPT-4-0613
- เวลาในการตอบสนอง (วินาที) – เวลาเฉลี่ยที่แต่ละโมเดลใช้ในการสร้างคำตอบ

เริ่มต้นใช้งาน TRAG Benchmark
ก้าวสู่แนวหน้าของเทคโนโลยีปัญญาประดิษฐ์ด้านภาษาไทยกับ TRAG Benchmark แพลตฟอร์มการประเมินที่ได้รับการออกแบบอย่างพิถีพิถันเพื่อประเมินและยกระดับความสามารถของโมเดลการเรียนรู้ภาษา (Language Learning Models: LLMs) ด้วยการประเมินโมเดลอย่างเข้มงวดในความหลากหลายทั้งมิติและหมวดหมู่ของกรณีทดสอบ TRAG ช่วยให้นักวิจัยและนักพัฒนาสามารถทดสอบประสิทธิภาพ ปรับปรุง และสร้างนวัตกรรมสำหรับโซลูชันปัญญาประดิษฐ์ของตนร่วมเป็นส่วนหนึ่งในการขับเคลื่อนอนาคตของเทคโนโลยีปัญญาประดิษฐ์ด้านภาษาไทย เราขอเชิญชวนนักวิจัยและนักพัฒนาใช้ TRAG Benchmark ในการประเมินและเปรียบเทียบประสิทธิภาพของโมเดลของท่าน เพื่อร่วมผลักดันความก้าวหน้าของเทคโนโลยีปัญญาประดิษฐ์ด้านภาษาไทย