


Agentic AI ตัวช่วยเจาะลึกข้อมูลอัจฉริยะแบบมือโปร
1. บทสรุป (Executive Summary)
ในยุคที่ข้อมูลมีปริมาณมหาศาล องค์กรต่าง ๆ เผชิญกับความท้าทายในการสกัดข้อมูลเชิงลึกที่สามารถนำไปใช้งานได้อย่างทันท่วงทีจากชุดข้อมูลที่มีความซับซ้อนเพิ่มขึ้นอย่างต่อเนื่อง วิธีการวิเคราะห์ข้อมูลแบบดั้งเดิมมักเป็นงานที่ใช้เวลามาก ทำด้วยมือ และขาดความสามารถในการขยายผลได้อย่างมีประสิทธิภาพ ซึ่งกลายเป็นอุปสรรคสำคัญในการค้นหารูปแบบเชิงลึกที่จำเป็นต่อการตัดสินใจเชิงกลยุทธ์
White Paper นี้นำเสนอเรื่อง Agentic AI for Deep Data Analysis ซึ่งเป็นวิธีการที่พลิกโฉมการวิเคราะห์ข้อมูล โดยใช้เอเจนต์ AI อัตโนมัติที่สามารถสำรวจและวิเคราะห์ข้อมูลด้วยตนเองในระดับสูงได้อย่างอิสระ หัวใจของกรอบการทำงานนี้คือความสามารถในการตีความ Natural Language Query (NLQ) เพื่อค้นหาข้อมูลที่เกี่ยวข้อง และใช้เอเจนต์ LLM (Large Language Models) หลายตัวในการวิเคราะห์เชิงลึก พร้อมสร้างคำแนะนำที่สามารถนำไปใช้งานได้จริง องค์ประกอบสำคัญอีกประการคือ Expert Alignment ที่เชื่อมโยงกระบวนการของ AI เข้ากับความรู้และแนวปฏิบัติเฉพาะของแต่ละอุตสาหกรรม เพื่อรับรองว่าผลลัพธ์ที่ได้มีความแม่นยำ สอดคล้องกับบริบท และเป็นไปตามข้อกำหนดที่เกี่ยวข้อง
Framework นี้ทำงานผ่าน 2 ขั้นตอนหลัก ได้แก่:
- Data Analysis: ซึ่งเน้นการสกัดข้อมูลเชิงลึกจากข้อมูลเชิงโครงสร้างและข้อมูลจากเว็บภายนอก
- Action Recommendation: ที่สร้างแนวทางเชิงกลยุทธ์ที่สามารถดำเนินการได้จริง โดยอ้างอิงจากการวิเคราะห์และแนวทางของผู้เชี่ยวชาญ
กรอบการทำงานนี้ช่วยแก้ไขข้อจำกัดสำคัญ เช่น การระบุแหล่งข้อมูลที่เกี่ยวข้อง, การเข้าใจโครงสร้างข้อมูล, การผนวกข้อกำหนดเฉพาะของแต่ละอุตสาหกรรม, และการรวมปัจจัยภายนอกเพื่อสร้างมุมมองที่ครอบคลุมยิ่งขึ้น
ตัวอย่างการใช้งานแสดงให้เห็นถึงความยืดหยุ่นของ Agentic AI ที่สามารถนำไปประยุกต์ใช้ในหลายอุตสาหกรรม เช่น
- การหาสาเหตุหลักของยอดขายที่ลดลงในธุรกิจค้าปลีก
- การวิเคราะห์การใช้งานเครือข่ายและการหยุดชะงักในอุตสาหกรรมโทรคมนาคม
- การทำความเข้าใจปัจจัยที่ทำให้ลูกค้าเลิกใช้บริการในธุรกิจต่าง ๆ
จากผลการใช้งานจริงในกรณีของธุรกิจค้าปลีก พบว่า Agentic AI มีประสิทธิภาพที่น่าพึงพอใจ โดยใช้กระบวนการประเมินแบบวนซ้ำ ซึ่งประกอบด้วยการเปรียบเทียบกับ baseline ของผู้เชี่ยวชาญ การให้คะแนนแบบ "LLM as a Judge" และการตรวจสอบซ้ำโดยมนุษย์ พบว่าความสามารถของระบบมีการพัฒนาอย่างมีนัยสำคัญ จนแสดงให้เห็นถึงศักยภาพในการทำงานที่เหนือกว่ามนุษย์ในงานวิเคราะห์ข้อมูลเชิงโครงสร้าง
แนวทางการพัฒนาในอนาคตจะมุ่งเน้นไปที่
- การสร้าง Agent Framework ที่แข็งแกร่ง พร้อม Expert Playbooks
- การวิเคราะห์ข้อมูลจากหลายแหล่ง (ทั้งข้อมูลส่วนตัว ข้อมูลสาธารณะ และข้อมูลที่ต้องใช้การรันโค้ด) ได้อย่างไร้รอยต่อ
- การพัฒนา grading framework ที่มีเกณฑ์ประเมินอย่างละเอียด เช่น Hallucination Rate, Scalability Score, Test Score และ Overall Score
- การตรวจสอบความสามารถของระบบด้วย Global Benchmarks เช่น DABStep Leaderboard และ DA-bench Leaderboard
Agentic AI for Deep Data Analysis คือแนวทางใหม่ในการวิเคราะห์ข้อมูลที่มีประสิทธิภาพ สามารถขยายตัวได้ และให้ข้อมูลเชิงลึกที่นำไปใช้ได้จริง ซึ่งจะช่วยให้องค์กรสามารถตัดสินใจด้วยข้อมูลได้ดียิ่งขึ้น โดยมี AI เป็นผู้ช่วยอัตโนมัติที่น่าเชื่อถือ
2. แนะนำ Agentic AI
ในยุคของ Big Data ความสามารถในการสกัดข้อมูลเชิงลึกอย่างมีประสิทธิภาพกลายเป็นปัจจัยสำคัญสำหรับองค์กร วิธีการวิเคราะห์ข้อมูลแบบดั้งเดิมมักต้องพึ่งพาการทำงานของมนุษย์จำนวนมาก ส่งผลให้ขาดความยืดหยุ่น และขยายผลได้ยาก Agentic AI ซึ่งเป็นแนวทางที่อาศัยเอเจนต์ AI อัตโนมัติ (Autonomous AI Agents) ได้เข้ามาเปลี่ยนโฉมการวิเคราะห์ข้อมูล ด้วยการเปิดโอกาสให้ระบบสามารถสำรวจชุดข้อมูลที่ซับซ้อนได้ด้วยตนเองอย่างชาญฉลาด
ด้วยการผสาน Agentic AI เข้ากับการวิเคราะห์ข้อมูลเชิงลึก องค์กรสามารถค้นหารูปแบบที่ซ่อนอยู่ซึ่งมีบทบาทสำคัญต่อการตัดสินใจ เช่น การหาสาเหตุที่แท้จริงของยอดขายที่ลดลงในอุตสาหกรรมค้าปลีก หรือการตรวจสอบธุรกรรมที่อาจบ่งบอกถึงปัญหาในเครือข่ายของอุตสาหกรรมโทรคมนาคม
Agentic AI นำเสนอกรอบการทำงานที่สามารถประยุกต์ใช้ได้กับหลากหลายอุตสาหกรรม โดยมีองค์ประกอบหลักคือระบบ Natural Language Query (NLQ) ที่สามารถแปนข้อความภาษามนุษย์ให้เป็นคำสั่ง SQL เพื่อดึงข้อมูลที่เกี่ยวข้องได้อย่างแม่นยำ นอกจากนี้ยังมีการใช้เอเจนต์ LLM (Large Language Models) หลายตัวเพื่อวิเคราะห์ข้อมูลในหลายมิติและหลายวัตถุประสงค์
อย่างไรก็ตาม การนำ Agentic AI มาใช้ก็ต้องเผชิญกับความท้าทายหลายประการ ได้แก่:
ความท้าทายหลัก (Challenges)
- การระบุและดึงข้อมูล (Data Identification & Retrieval):
ระบบต้องสามารถระบุได้อย่างถูกต้องว่าควรค้นหาข้อมูลใดจากคำถามที่ได้รับ และดึงข้อมูลที่เกี่ยวข้องได้อย่างแม่นยำ - ความเข้าใจโครงสร้างข้อมูล (Understanding Data Structure):
ระบบต้องเข้าใจโครงสร้างของข้อมูลที่จัดเก็บอยู่ในฐานข้อมูลของอุตสาหกรรมแต่ละประเภท และสามารถใช้คำสั่งที่ถูกต้องในการดึงข้อมูลออกมาได้อย่างมีประสิทธิภาพ - การปฏิบัติตามข้อกำหนดเฉพาะอุตสาหกรรม (Industry-Specific Compliance):
แต่ละอุตสาหกรรมมีแนวปฏิบัติและข้อกำหนดเฉพาะที่ระบุขอบเขตของสิ่งที่สามารถกระทำได้ ระบบจะต้องปฏิบัติตามข้อกำหนดเหล่านี้อย่างเคร่งครัดเพื่อให้แน่ใจว่าเป็นไปตามข้อบังคับ - ข้อจำกัดของความรู้ในอุตสาหกรรม (Limitations of Industry Knowledge):
การอ้างอิงเฉพาะแนวปฏิบัติในอุตสาหกรรมอาจไม่ครอบคลุมทุกมิติของการวิเคราะห์ การนำข้อมูลจากภายนอกเข้ามาช่วยสามารถขยายขอบเขตความรู้และมุมมองใหม่ ๆ ได้ - การรวมปัจจัยภายนอก (Incorporating External Factors):
ปัจจัยภายนอกสามารถมีผลกระทบต่อการวิเคราะห์ได้อย่างมาก ระบบจึงควรสามารถรวมข้อมูลภายนอกที่เกี่ยวข้องเข้ามาเป็นส่วนหนึ่งของกระบวนการวิเคราะห์ได้อย่างไร้รอยต่อ
3. Agentic AI for Deep Data Analysis framework
Agentic AI for Deep Data Analysis แบ่งออกเป็น 2 ขั้นตอนหลัก ได้แก่ การวิเคราะห์ข้อมูล (data analysis) และการแนะนำแนวทางปฏิบัติ (action recommendation) โดยในขั้นตอนแรก ระบบจะมุ่งเน้นไปที่การวิเคราะห์ข้อมูลอย่างลึกซึ้ง ขณะที่ในขั้นตอนถัดไปจะเป็นการให้คำแนะนำที่สามารถนำไปใช้ได้จริง จากข้อมูลเชิงลึกที่ได้จากขั้นแรก
ในแต่ละขั้นตอน จะมี Agent หลายตัวทำงานร่วมกันเพื่อวิเคราะห์ข้อมูลและจัดทำรายงานขั้นสุดท้าย Framework นี้ให้ภาพรวมของกระบวนการ โดยไม่ได้ลงลึกในรายละเอียดของ Agent ที่ทำหน้าที่ในแต่ละส่วน นอกจากนี้ยังมี “Expert Alignment” ซึ่งมีบทบาทสำคัญในทั้งสองขั้นตอน โดยเป็นพื้นฐานของความรู้ที่ช่วยกำหนดแนวทางการทำงานของ Agent ให้มีความแม่นยำ สอดคล้อง และเป็นไปตามมาตรฐานของอุตสาหกรรม
Expert Alignment
Expert alignment คือกระบวนการจัดเตรียมความรู้พื้นฐานให้กับ Large Language Model (LLM) เพื่อให้สามารถทำงานในลักษณะของผู้เชี่ยวชาญ โดยจะอาศัยการรวบรวมองค์ความรู้และแนวทางจากผู้เชี่ยวชาญในอุตสาหกรรม ซึ่งจะกลายเป็นแนวทางอ้างอิงสำหรับ LLM ในการประมวลผล วิเคราะห์ข้อมูล และตัดสินใจ
เมื่อ LLM ได้รับการปรับให้มี expert alignment ระบบจะเข้าใจวิธีการจัดการกับข้อมูลที่ซับซ้อน สามารถวิเคราะห์ปัญหา และเสนอแนวทางที่ใช้งานได้จริง ซึ่งสะท้อนถึงวิจารณญาณและการตัดสินใจในระดับผู้เชี่ยวชาญ กล่าวโดยสรุป Expert Alignment ทำหน้าที่เป็นโครงสร้างพื้นฐานที่ชี้นำให้ LLM ดำเนินการได้อย่างมีประสิทธิภาพและสม่ำเสมอในทุกบริบทของงาน
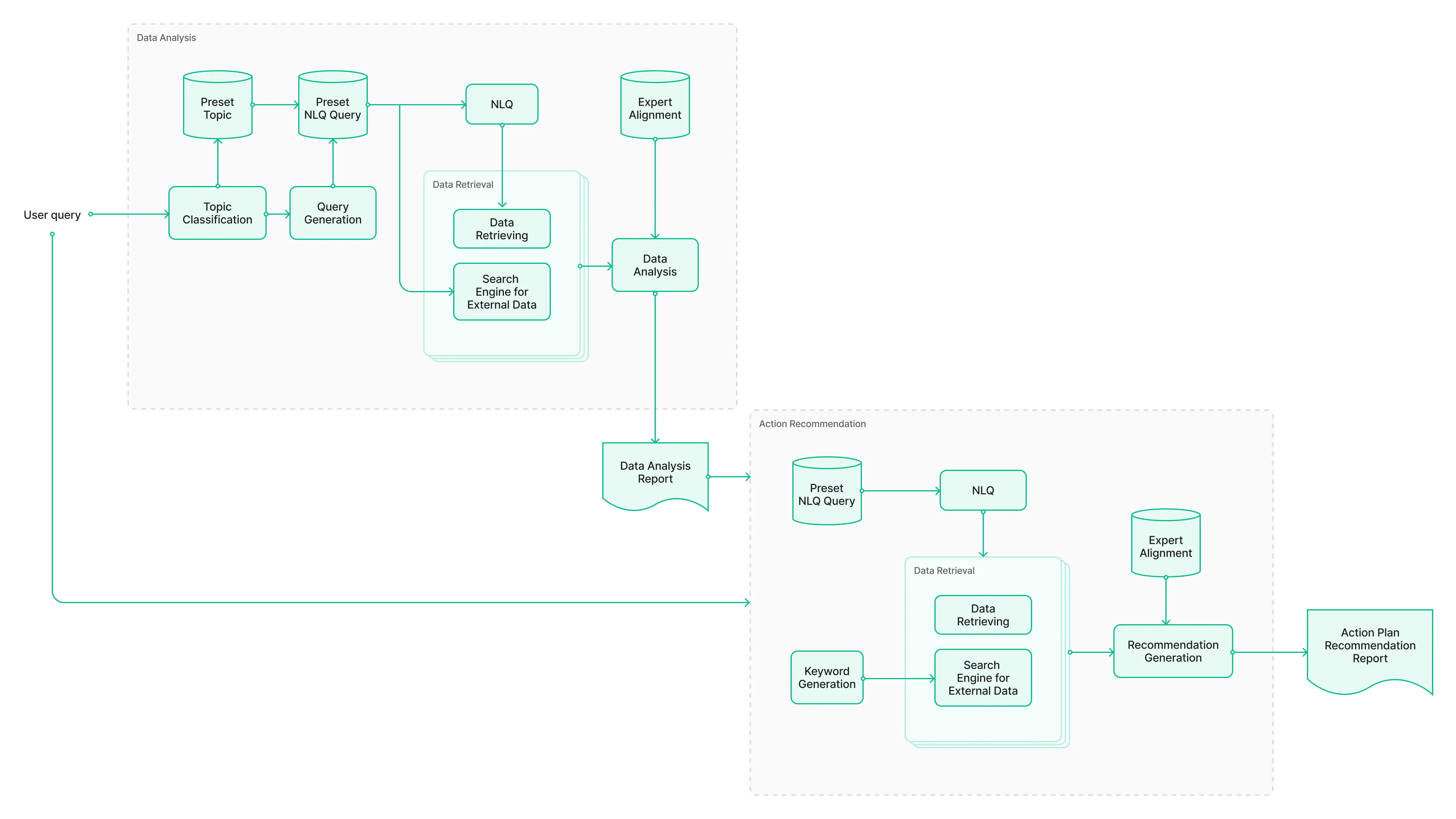
ขั้นตอนที่ 1: การวิเคราะห์ข้อมูล (Data Analysis)
กระบวนการวิเคราะห์ข้อมูลมีเป้าหมายเพื่อดึงข้อมูลเชิงลึกจากคำถามของผู้ใช้ โดยเริ่มจากการแปลงคำถามที่อยู่ในรูปแบบภาษาธรรมชาติ (natural language) ให้เป็น SQL query เพื่อนำข้อมูลที่มีโครงสร้างมาใช้ในการวิเคราะห์ พร้อมทั้งค้นหาปัจจัยภายนอกที่เกี่ยวข้องจากอินเทอร์เน็ต
เพื่อระบุว่าควรใช้ข้อมูลใด หัวข้อของ SQL query จะถูกกำหนดไว้ล่วงหน้าตามแนวทางมาตรฐานในแต่ละอุตสาหกรรม จากนั้นระบบ NLQ (Natural Language Query) จะดึงข้อมูลตามหัวข้อที่สอดคล้อง พร้อมผลลัพธ์จากการค้นหาทางอินเทอร์เน็ต ซึ่งทั้งหมดนี้จะถูกนำเข้าสู่โมดูลวิเคราะห์ข้อมูล โดยใช้โมเดล LLM ที่มีความสามารถด้าน reasoning (การใช้เหตุผล) ผ่านเทคนิคการ prompt ที่ออกแบบให้สอดคล้องกับแนวปฏิบัติที่ดีที่สุดในอุตสาหกรรม เพื่อให้ผลลัพธ์มีความแม่นยำและสามารถใช้งานได้จริง
1. Topic Classification
กระบวนการนี้เป็นการระบุว่าคำถามของผู้ใช้อยู่ในหมวดหมู่หัวข้อใด ซึ่งจะเป็นตัวกำหนดว่า ระบบควรใช้ชุดคำถาม NLQ ที่ถูกกำหนดไว้ล่วงหน้าแบบใดในการดึงข้อมูล ตัวอย่างเช่น หากระบบจัดหมวดคำถามไว้เป็น Topic A, B, C ฯลฯ เมื่อระบบระบุได้ว่าคำถามอยู่ในหัวข้อ A ก็จะรู้ทันทีว่าควรใช้ชุดคำถาม NLQ แบบใดในการเรียกข้อมูลให้ตรงจุด
2. Query Generation
ขั้นตอนนี้คือการสร้าง query เพื่อใช้งานจริง โดยผสานข้อมูลบริบทเพิ่มเติมจากขั้นตอนก่อนหน้า ซึ่งรวมถึงหัวข้อที่ถูกจำแนก และข้อมูลเบื้องต้นที่ได้จาก preset data ทั้งนี้เพื่อปรับขอบเขตของ NLQ ให้แม่นยำ และกำหนดคีย์เวิร์ดที่เหมาะสมสำหรับการค้นหาทางอินเทอร์เน็ต
ตัวอย่างเช่น หากต้องการวิเคราะห์สาเหตุของปัญหาในธุรกิจค้าปลีก ระบบจะวิเคราะห์ว่าเกิดปัญหาในช่องทางธุรกิจใดมากที่สุด (เช่น B2B หรือ B2C) แล้วจึงจำกัดขอบเขตของ query ให้เน้นเฉพาะข้อมูลในช่องทางนั้น
3. Data Retrieval
ในขั้นตอนนี้ ระบบจะรวบรวมข้อมูลจาก 2 แหล่งหลัก ได้แก่
- NLQ system – ทำหน้าที่รัน structured query เพื่อดึงข้อมูลจากฐานข้อมูลภายในองค์กร
- Web search engine – ที่ขับเคลื่อนด้วย LLM เพื่อประมวลผลคำค้นหาและรวบรวมข้อมูลภายนอกจากอินเทอร์เน็ต
ข้อมูลทั้งสองแหล่งจะถูกผสานกันเพื่อสร้างบริบทที่ครอบคลุมสำหรับการวิเคราะห์ในขั้นต่อไป
4. Data Analysis
เมื่อได้ข้อมูลครบถ้วน ระบบจะใช้ LLM ที่มีความสามารถในการ reasoning เพื่อทำการวิเคราะห์ โดยจะประมวลผลทั้งข้อมูลเชิงโครงสร้าง (structured data) จากระบบ NLQ และข้อมูลภายนอกจากอินเทอร์เน็ต พร้อม prompt ที่ออกแบบมาให้สอดคล้องกับมาตรฐานของอุตสาหกรรม เพื่อให้การวิเคราะห์สามารถระบุข้อมูลเชิงลึก (insights), แพทเทิร์น และแนวทางตัดสินใจได้อย่างมีประสิทธิภาพ
ดูเพิ่มเติมที่: NLQ version 1
ขั้นตอนที่ 2: การแนะนำแนวทางดำเนินการ (Action Recommendation)
เช่นเดียวกับกระบวนการวิเคราะห์ข้อมูล ระยะของการเชื่อมโยงข้อมูล (grounding) นี้จะใช้การดึงข้อมูลจากระบบถามตอบภาษาธรรมชาติ (NLQ) และการค้นหาทางอินเทอร์เน็ต โดยในระยะนี้จะนำรายงานการวิเคราะห์ข้อมูลจากระยะที่หนึ่งมาใช้ร่วมกับคำถามของผู้ใช้ เพื่อให้แน่ใจว่าแนวทางที่แนะนำนั้นสอดคล้องกับข้อมูลเชิงลึกที่ได้วิเคราะห์มา
การสร้างคำแนะนำ ระบบจะใช้เทคนิคการตั้งคำสั่ง (prompting techniques) กับโมเดลการให้เหตุผลของ LLM เพื่อสร้างแนวทางการดำเนินการที่อิงกับแนวทางมาตรฐานในแต่ละอุตสาหกรรม โดยคำแนะนำที่ได้จะเน้นความเป็นไปได้ในการนำไปปฏิบัติจริงและสอดคล้องกับแนวทางปฏิบัติในภาคธุรกิจ
- การสร้างคีย์เวิร์ด (Keyword Generation)
ในขั้นตอนนี้ ระบบจะวิเคราะห์คำถามของผู้ใช้และรายงานการวิเคราะห์ข้อมูล เพื่อดึงคำสำคัญ (keywords) ที่เกี่ยวข้องออกมา จากนั้นจะใช้คำเหล่านี้ในการค้นหากรณีศึกษาที่ประสบความสำเร็จ หรือรูปแบบการใช้งานจริง เพื่อเป็นองค์ความรู้เพิ่มเติมให้กับ LLM ซึ่งจะถูกนำมาผสานกับข้อมูลจากระบบ NLQ เพื่อช่วยในการแนะนำแนวทางปฏิบัติ
- การดึงข้อมูล (Data Retrieval)
จากคีย์เวิร์ดที่ได้ในขั้นตอนก่อนหน้า ระบบจะค้นหาข้อมูลจากอินเทอร์เน็ต เช่น กรณีศึกษา แนวปฏิบัติที่ดีที่สุด (best practices) หรือเรื่องราวความสำเร็จต่าง ๆ นอกจากนี้ยังสามารถดึงข้อมูลเชิงโครงสร้างเพิ่มเติมจากระบบ NLQ ได้อีกด้วย เพื่อเสริมความสมบูรณ์ของกระบวนการแนะนำ
- การสร้างคำแนะนำ (Recommendation Generation)
เมื่อรวบรวมข้อมูลทั้งหมดแล้ว ไม่ว่าจะเป็นคำถามของผู้ใช้ รายงานวิเคราะห์ คำสำคัญ และข้อมูลที่ค้นหาได้ โมเดล LLM จะประมวลผลร่วมกันเพื่อสร้างคำแนะนำที่สามารถนำไปปฏิบัติได้จริง โดยคำแนะนำเหล่านี้จะสอดคล้องกับมาตรฐานในอุตสาหกรรม และปรับให้เหมาะสมกับบริบทเฉพาะของคำถามและข้อมูลที่มีของผู้ใช้
4. ตัวอย่างการใช้งานจริง
ตัวอย่างที่ 1: การวิเคราะห์สาเหตุและการแนะนำแนวทางแก้ไขปัญหาในอุตสาหกรรมค้าปลีก
การวิเคราะห์สาเหตุเชิงลึกของปัญหาที่เกิดขึ้นในอุตสาหกรรมค้าปลีก พร้อมเสนอแนวทางแก้ไขเพื่อยกระดับยอดขาย การดำเนินงาน และความพึงพอใจของลูกค้า
คำถามจากผู้ใช้: เหตุใดยอดขายของสาขา AA จึงลดลงอย่างมาก?
การวิเคราะห์สาเหตุที่แท้จริง
- การวิเคราะห์ข้อมูลและข้อมูลเชิงลึก
- ยอดขายลดลง: ยอดขายลดลงอย่างต่อเนื่องตั้งแต่ไตรมาสที่ 1 ถึงไตรมาสที่ 4 โดยเฉพาะใน ไตรมาสที่ 4 ซึ่งเป็นช่วงเทศกาลที่มักจะมียอดขายสูงสุดสำหรับธุรกิจค้าปลีก
- จำนวนลูกค้าที่เข้าร้านลดลง: จำนวนลูกค้าลดลงถึง 30% จากไตรมาสที่ 1 ถึงไตรมาสที่ 4
- ระยะเวลาการชำระเงินที่นานขึ้น: เวลาเฉลี่ยในการชำระเงินเพิ่มขึ้นจาก 5 นาทีในไตรมาสแรกเป็น 10 นาทีในไตรมาสที่ 4
- จำนวนคำร้องเรียนของลูกค้าเพิ่มขึ้น: คำร้องเรียนจากลูกค้าเพิ่มจากเฉลี่ย 25 ครั้งต่อสัปดาห์ในไตรมาสแรกเป็น 75 ครั้งในไตรมาสที่ 4 โดยมีแนวโน้มว่ามีสาเหตุมาจากการรอนาน การบริการที่ไม่ดี หรือปัญหาสินค้าขาดสต็อก
- สินค้าขายดีขาดสต็อก: ตั้งแต่ไตรมาสที่ 2 เป็นต้นมา พบว่ามีสินค้าขายดีขาดสต็อกต่อเนื่อง โดยเฉพาะในไตรมาสที่ 4 ซึ่งเป็นช่วงที่ความต้องการสูง ส่งผลให้ลูกค้าไม่พอใจและพลาดโอกาสการขายจำนวนมาก
- สาเหตุที่แท้จริง
- ขั้นตอนการชำระเงินไม่มีประสิทธิภาพ: การที่ใช้เวลาชำระเงินเพิ่มขึ้นอย่างมากในช่วงเวลาที่ลูกค้าหนาแน่น เป็นปัญหาคอขวดที่สำคัญ และมีแนวโน้มสูงที่จะทำให้ลูกค้าไม่พอใจหรือยกเลิกการซื้อของไป
- ปัญหาการจัดการสต็อกสินค้า: การไม่มีสินค้ายอดนิยมเพียงพอต่อความต้องการ ทำให้ลูกค้าเลือกไปซื้อจากร้านอื่น ส่งผลให้พลาดรายได้
- จำนวนลูกค้าเข้าร้านลดลง: การที่ลูกค้าเข้าร้านน้อยลงถึง 30% โดยเฉพาะในช่วงปลายปี อาจสะท้อนถึงกิจกรรมการตลาดที่ไม่ตรงใจกลุ่มเป้าหมาย และประสบการณ์ที่ไม่ดีในการซื้อของ (เช่น ต้องรอนาน หรือสินค้าไม่มี) อาจทำให้ลูกค้าไม่กลับมาใช้บริการซ้ำ
แนวทางแนะนำ
- ปรับปรุงกระบวนการชำระเงิน:
- เพิ่มจำนวนพนักงานที่แคชเชียร์ในช่วงเวลาที่ลูกค้าหนาแน่น เพื่อลดระยะเวลารอคิว
- ติดตั้งเครื่องชำระเงินแบบ Self-Checkout เพื่อช่วยลดความแออัดที่จุดชำระเงินหลัก
- พัฒนาระบบ point-of-sale (POS) ให้ทำงานได้รวดเร็วและมีประสิทธิภาพมากขึ้น เพื่อเร่งกระบวนการชำระเงิน
- การบริหารจัดการสต็อกสินค้า:
- ใช้ระบบจัดการคลังสินค้าที่มีความแม่นยำมากขึ้น สามารถคาดการณ์ความต้องการของลูกค้าและลดโอกาสสินค้าขาดสต็อก โดยเฉพาะสินค้ายอดนิยม
- นำระบบติดตามสต็อกแบบเรียลไทม์ พร้อมระบบแจ้งเตือนเมื่อสินค้าใกล้หมด เพื่อให้สามารถเติมสินค้าได้ทันเวลา
- การตลาดและการสร้างความผูกพันกับลูกค้า:
- จัดแคมเปญการตลาดแบบเจาะกลุ่มเป้าหมาย โดยเฉพาะในช่วงเวลาขายดี เพื่อดึงดูดลูกค้าให้กลับเข้าร้าน
- สร้างความสัมพันธ์กับลูกค้าผ่านโปรโมชั่นเฉพาะบุคคล โปรแกรมสะสมแต้ม และการติดตามผลหลังการซื้อ เช่น การส่งอีเมลขอบคุณหรือเสนอส่วนลดสำหรับการซื้อครั้งถัดไป
- ระบบรับฟังความคิดเห็นจากลูกค้า
- วางระบบรับฟังความคิดเห็นของลูกค้าที่ใช้งานง่าย ทั้งในระหว่างและหลังการซื้อ เพื่อเก็บข้อมูลเชิงลึกเกี่ยวกับประสบการณ์การใช้งาน
- ใช้ข้อมูลนี้เพื่อระบุปัญหาหรือจุดที่ลูกค้าไม่พอใจได้อย่างรวดเร็ว และปรับปรุงบริการให้ดียิ่งขึ้น
ตัวอย่างที่ 2: การวิเคราะห์ข้อมูลสำหรับการใช้งานเครือข่ายในอุตสาหกรรมโทรคมนาคม
การวิเคราะห์รูปแบบการใช้งานเครือข่ายเพื่อปรับปรุงประสิทธิภาพการทำงาน ตรวจจับปัญหา และปรับปรุงคุณภาพการบริการในภาคโทรคมนาคม
คำถามผู้ใช้: ทำไมบางพื้นที่ถึงเกิดปัญหาสัญญาณขัดข้องเป็นระยะ?
การวิเคราะห์ข้อมูล
- การใช้งานเครือข่าย:
- พื้นที่ A: การใช้งานเครือข่ายอยู่ที่ 85% ซึ่งค่อนข้างดีและบ่งชี้ว่าเครือข่ายไม่ได้ถูกใช้งานมากเกินไป
- พื้นที่ B: การใช้งานเครือข่ายอยู่ที่ 95% ซึ่งบ่งชี้ถึงภาระงานที่หนัก อาจทำให้เกิดปัญหาความล่าช้าหรือขัดข้อง
- การหยุดบริการ:
- พื้นที่ A: มีรายงานการหยุดบริการเพียง 2 ครั้ง ซึ่งบ่งชี้ว่าเครือข่ายทำงานได้ดีและสามารถจัดการกับความหนาแน่นของผู้ใช้งานได้โดยไม่มีการหยุดชะงักมากนัก
- พื้นที่ B: มีการหยุดบริการที่สูงกว่าอย่างมีนัยสำคัญ (15 ครั้ง) เกิดขึ้นในพื้นที่ B แม้จะมีการใช้งานเครือข่ายสูง สิ่งนี้บ่งชี้ว่าการใช้งานที่สูงอาจทำให้เกิดความไม่เสถียรหรือมีข้อจำกัดด้านโครงสร้างพื้นฐานที่ส่งผลต่อการหยุดชะงักเหล่านี้
ข้อมูลเชิงลึกที่เป็นไปได้
- พื้นที่ A: ด้วยการใช้งานเครือข่ายเพียง 85% และการหยุดชะงักน้อยที่สุด ภูมิภาค A ทำงานภายใต้สภาวะที่เหมาะสม เครือข่ายดูเหมือนจะได้รับการติดตั้งอย่างดีเพื่อรองรับระดับการใช้งานปัจจุบัน และจำนวนการหยุดบริการที่ต่ำบ่งชี้ถึงสภาพเครือข่ายที่ดี
- พื้นที่ B: การใช้งานเครือข่ายสูง (95%) ควบคู่ไปกับการหยุดบริการ 15 ครั้งบ่งชี้ว่าภูมิภาค B กำลังประสบกับความแออัดของเครือข่าย สิ่งนี้อาจเกิดจากความหนาแน่นของผู้ใช้สูงหรือข้อจำกัดด้านโครงสร้างพื้นฐาน (เช่น แบนด์วิดท์ไม่เพียงพอ, ฮาร์ดแวร์ล้าสมัย ฯลฯ) การรวมกันของการใช้งานสูงและการหยุดบริการบ่อยครั้ง บ่งชี้ว่าเครือข่ายที่ไม่สามารถรองรับความต้องการได้ทัน ทำให้เกิดการหยุดชะงัก
ตัวอย่างที่ 3: วิเคราะห์ปัญหาลูกค้าเลิกใช้บริการทางธุรกิจ
การระบุปัจจัยที่ส่งผลต่อการสูญเสียลูกค้าและการแนะนำกลยุทธ์เพื่อรักษาลูกค้าที่มีคุณภาพในภาคธุรกิจต่างๆ
คำถามผู้ใช้: ทำไมบริษัทจึงประสบกับการเพิ่มขึ้นของการสูญเสียลูกค้า?
การวิเคราะห์ข้อมูล
- อัตราการรักษาลูกค้า (Customer Retention Rate):
- อัตราการสูญเสียลูกค้า (Churn Rate): จากลูกค้า 300 คน (250 คนที่อยู่ต่อและ 50 คนที่ยกเลิก) อัตราการสูญเสียลูกค้าคือ 16.7% [(50 คนที่ยกเลิก / 300 คนทั้งหมด) * 100]
- การสูญเสียรายได้จากการสมัครสมาชิก (Subscription Revenue Loss): บริษัทสูญเสียรายได้ 20 ดอลลาร์ต่อเดือนจากลูกค้าที่ยกเลิกแต่ละราย ส่งผลให้สูญเสียรายได้ 1,000 ดอลลาร์ต่อเดือนจากการสูญเสียลูกค้าเพียงอย่างเดียว
- การวิเคราะห์การใช้งาน:
- ลูกค้าที่ยกเลิก: ลูกค้าที่ยกเลิกมีการใช้งานเฉลี่ย 5 ชั่วโมงต่อสัปดาห์ ซึ่งบ่งชี้ถึงการมีส่วนร่วมต่ำกับแพลตฟอร์ม
- ลูกค้าที่ไม่ยกเลิก: ลูกค้าที่ยังคงอยู่บนแพลตฟอร์มมีส่วนร่วมสูงกว่าอย่างมีนัยสำคัญ โดยเฉลี่ย 15 ชั่วโมงต่อสัปดาห์
- ความแตกต่างอย่างมากของจำนวนชั่วโมงในการใช้งานระหว่างลูกค้าที่ยกเลิกและไม่ยกเลิกบ่งชี้ว่าการใช้งานที่ต่ำกว่าเป็นตัวทำนายสำคัญของการสูญเสียลูกค้า
- การมีส่วนร่วมของลูกค้า:
- ลูกค้าที่ยกเลิกดูเหมือนจะมีส่วนร่วมกับแพลตฟอร์มน้อยกว่าเมื่อเทียบกับผู้ที่ยังคงอยู่ การมีส่วนร่วมต่ำนี้อาจบ่งชี้ว่าคุณค่าหรือประโยชน์ของแพลตฟอร์มไม่ชัดเจนสำหรับลูกค้าที่ยกเลิก หรือพวกเขาอาจไม่ได้มีปฏิสัมพันธ์กับแพลตฟอร์มมากพอที่จะเห็นศักยภาพเต็มที่
ข้อมูลเชิงลึกที่เป็นไปได้
- การมีส่วนร่วมต่ำ: การลดลงอย่างมีนัยสำคัญในการใช้งานระหว่างลูกค้าที่ยกเลิก (5 ชั่วโมง/สัปดาห์) และลูกค้าที่ไม่ยกเลิก (15 ชั่วโมง/สัปดาห์) บ่งชี้ว่าการใช้งานที่ต่ำกว่านำไปสู่การสูญเสียลูกค้าที่สูงขึ้น ลูกค้าที่ไม่ได้มีปฏิสัมพันธ์กับแพลตฟอร์มมากพออาจไม่รู้สึกถึงการเชื่อมต่อหรือไม่พบคุณค่าเพียงพอที่จะชำระเงินค่าบริการต่อไป
- ปัจจัยเสี่ยงของการสูญเสียลูกค้า: อัตราการสูญเสียลูกค้าดูเหมือนจะสูงขึ้นในกลุ่มลูกค้าที่มีส่วนร่วมน้อยกว่า ซึ่งบ่งชี้ว่าการมีส่วนร่วมของลูกค้าเป็นปัจจัยสำคัญในการรักษาลูกค้า การมีส่วนร่วมต่ำนี้อาจเกี่ยวข้องกับการขาดการให้ความรู้เบื้องต้น, การตระหนักถึงคุณสมบัติของแพลตฟอร์ม, หรือการใช้ประโยชน์จากความสามารถไม่เต็มที่
5. ผลลัพธ์การใช้งานในโลกแห่งความเป็นจริง
การวิเคราะห์สาเหตุที่แท้จริงและการแนะนำการดำเนินการสำหรับอุตสาหกรรมค้าปลีก
เฟรมเวิร์ก AI อัจฉริยะได้รับการทดสอบในสถานการณ์อุตสาหกรรมค้าปลีกสำหรับการวิเคราะห์สาเหตุที่แท้จริงและการแนะนำการดำเนินการ
เพื่อประเมินประสิทธิผลของเฟรมเวิร์ก AI อัจฉริยะเมื่อเทียบกับกระบวนการที่นำโดยมนุษย์แบบดั้งเดิม ได้มีการวัดอัตราการยอมรับในขั้นตอนต่างๆ:
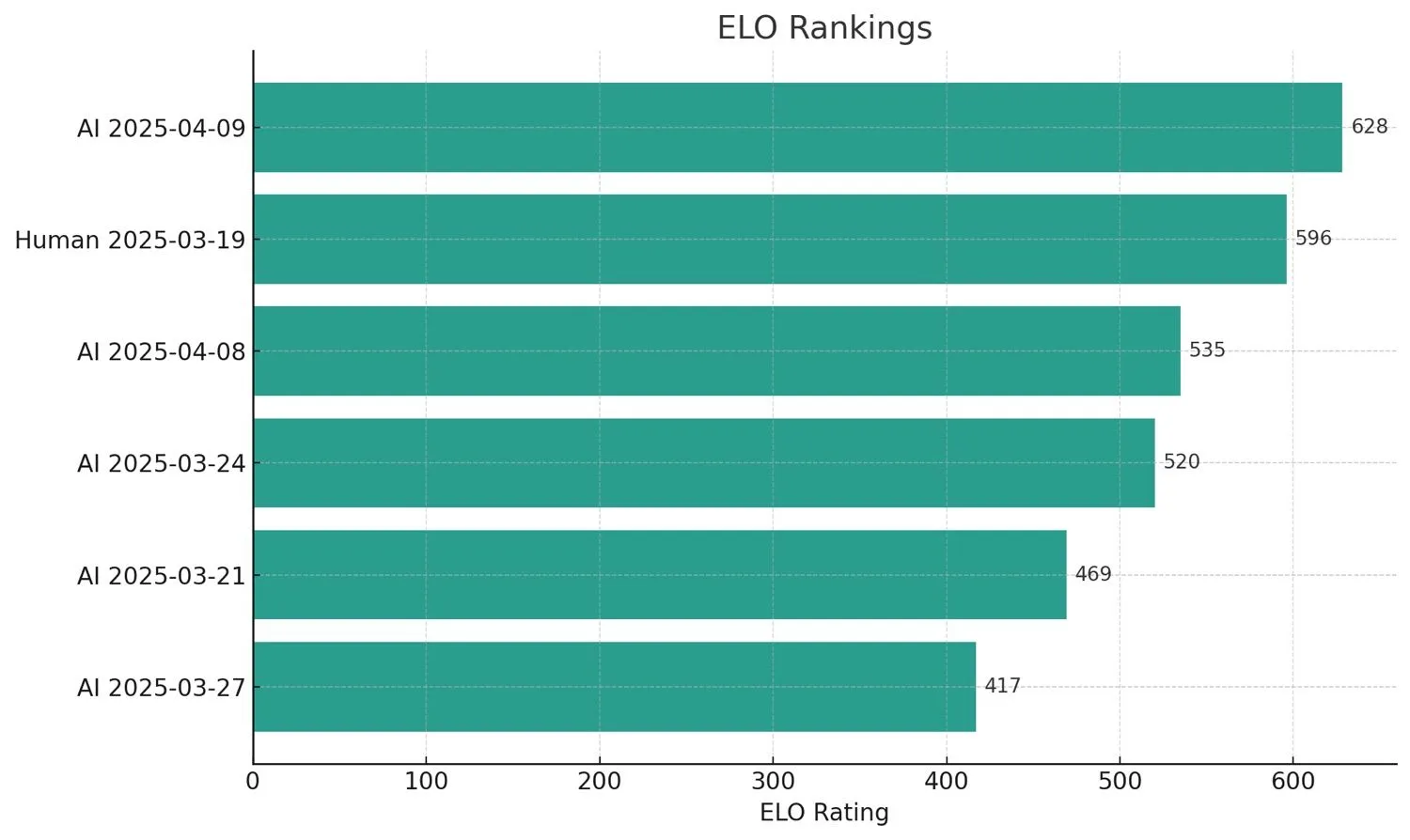
กรอบการประเมินนี้ใช้กระบวนการหลายขั้นตอนเพื่อประเมินและปรับปรุงประสิทธิภาพของ AI อัจฉริยะ โดยบูรณาการความเชี่ยวชาญของมนุษย์และการให้คะแนนอัตโนมัติ
ใช้ผู้เชี่ยวชาญเป็นแนวทาง
กระบวนการเริ่มต้นด้วยการสร้างพื้นฐานโดยใช้ผู้เชี่ยวชาญ ตามการจัดอันดับ ELO (เช่น มนุษย์ 2025-03-12 ที่ 562.07, มนุษย์ 2025-03-19 ที่ 596.11) การจัดอันดับเหล่านี้ทำหน้าที่เป็นมาตรฐานเริ่มต้นและเป้าหมายสำหรับ AI อัจฉริยะ ความเชี่ยวชาญที่ฝังอยู่ในประสิทธิภาพของมนุษย์ชี้นำการพัฒนาและการปรับปรุงโมเดล AI
AI อัจฉริยะ (ขั้นตอนเริ่มต้น)
ในการใช้งานเริ่มต้น ประสิทธิภาพของ AI อัจฉริยะจะถูกวัด โดยใช้ผลการจัดอันดับ ELO เช่น AI 2025-03-27 ที่ 417.14, AI 2025-03-21 ที่ 468.76 และ AI 2025-03-24 ที่ 519.61 การจัดอันดับเริ่มต้นเหล่านี้บ่งชี้ว่าในขณะที่ AI ทำงานได้ แต่ยังมีช่องว่างด้านประสิทธิภาพเมื่อเทียบกับพื้นฐานของมนุษย์ โดยจะต้องมีการปรับปรุงในการให้เหตุผลและคุณภาพของผลลัพธ์
การให้คะแนนโดย "LLM as a Judge" และการตรวจสอบซ้ำโดยผู้เชี่ยวชาญมนุษย์
หลังจากการประเมินเบื้องต้น ได้มีการนำกระบวนการวนซ้ำของข้อเสนอแนะและการปรับมาใช้ สิ่งนี้เกี่ยวข้องกับการให้คะแนนผลลัพธ์ของ AI อัจฉริยะ โดยอาจใช้กลไก "LLM as a Judge" สำหรับการประเมินอัตโนมัติ ตามด้วยการตรวจสอบซ้ำโดยผู้เชี่ยวชาญมนุษย์ ขั้นตอนการตรวจสอบความถูกต้องนี้ให้ข้อมูลเชิงลึกที่สำคัญเกี่ยวกับความแตกต่างและพื้นที่ที่ประสิทธิภาพของ AI แตกต่างจากความคาดหวังของผู้เชี่ยวชาญ มีการปรับเวิร์กโฟลว์ตามข้อเสนอแนะนี้ รวมถึงการปรับปรุงอินพุตข้อมูล การปรับปรุงกระบวนการภายใน (เช่น การสร้างคำสำคัญ) และการปรับกลยุทธ์การกระตุ้นเพื่อปรับการตัดสินใจของ AI ให้สอดคล้องกับการตัดสินของผู้เชี่ยวชาญได้ดีขึ้น ระบบการจัดอันดับ ELO เองสะท้อนผลลัพธ์ของการเปรียบเทียบและการตรวจสอบเหล่านี้ โดยทำหน้าที่เป็นเมตริกเพื่อแสดงถึงประสิทธิภาพ
Agentic AI (ระยะที่พัฒนาแล้ว)
หลังจากการปรับปรุงครั้งสำคัญและการปรับแต่งซ้ำหลายรอบตามคำแนะนำจากผู้เชี่ยวชาญและการตรวจสอบผลอย่างต่อเนื่อง ประสิทธิภาพของ Agentic AI ก็พัฒนาขึ้นอย่างชัดเจน โดยสามารถเห็นได้จากค่า ELO ที่สูงขึ้นในเวอร์ชันหลัง เช่น AI รุ่นวันที่ 8 เมษายน 2025 ซึ่งมีค่า ELO อยู่ที่ 534.54 และโดยเฉพาะอย่างยิ่งรุ่นวันที่ 9 เมษายน 2025 ที่เพิ่มขึ้นเป็น 627.87
AI เวอร์ชันล่าสุดนี้มีค่า ELO สูงกว่าค่าเฉลี่ยของมนุษย์ สะท้อนถึงการพัฒนาทั้งในด้านคุณภาพ ความแม่นยำ และความเกี่ยวข้องของผลลัพธ์ที่สร้างขึ้น โดยสามารถผลิตผลลัพธ์ที่สอดคล้องหรือเหนือกว่ามาตรฐานของผู้เชี่ยวชาญ ผ่านกระบวนการประเมินและปรับปรุงอย่างเป็นระบบในแต่ละรอบของการพัฒนา
6. งานวิจัยในอนาคต
ต่อยอดจากความสำเร็จในการพัฒนา AI ให้มีประสิทธิภาพสูงผ่านการปรับแต่งอย่างต่อเนื่องและคำแนะนำจากผู้เชี่ยวชาญ งานวิจัยในอนาคตจะมุ่งเน้นไปที่การพัฒนาและนำระบบ Agent Framework ออกใช้งานอย่างเต็มรูปแบบ เพื่อให้ Agent สามารถวิเคราะห์ข้อมูลที่ซับซ้อนได้อย่างเชี่ยวชาญในระดับเดียวกับมนุษย์
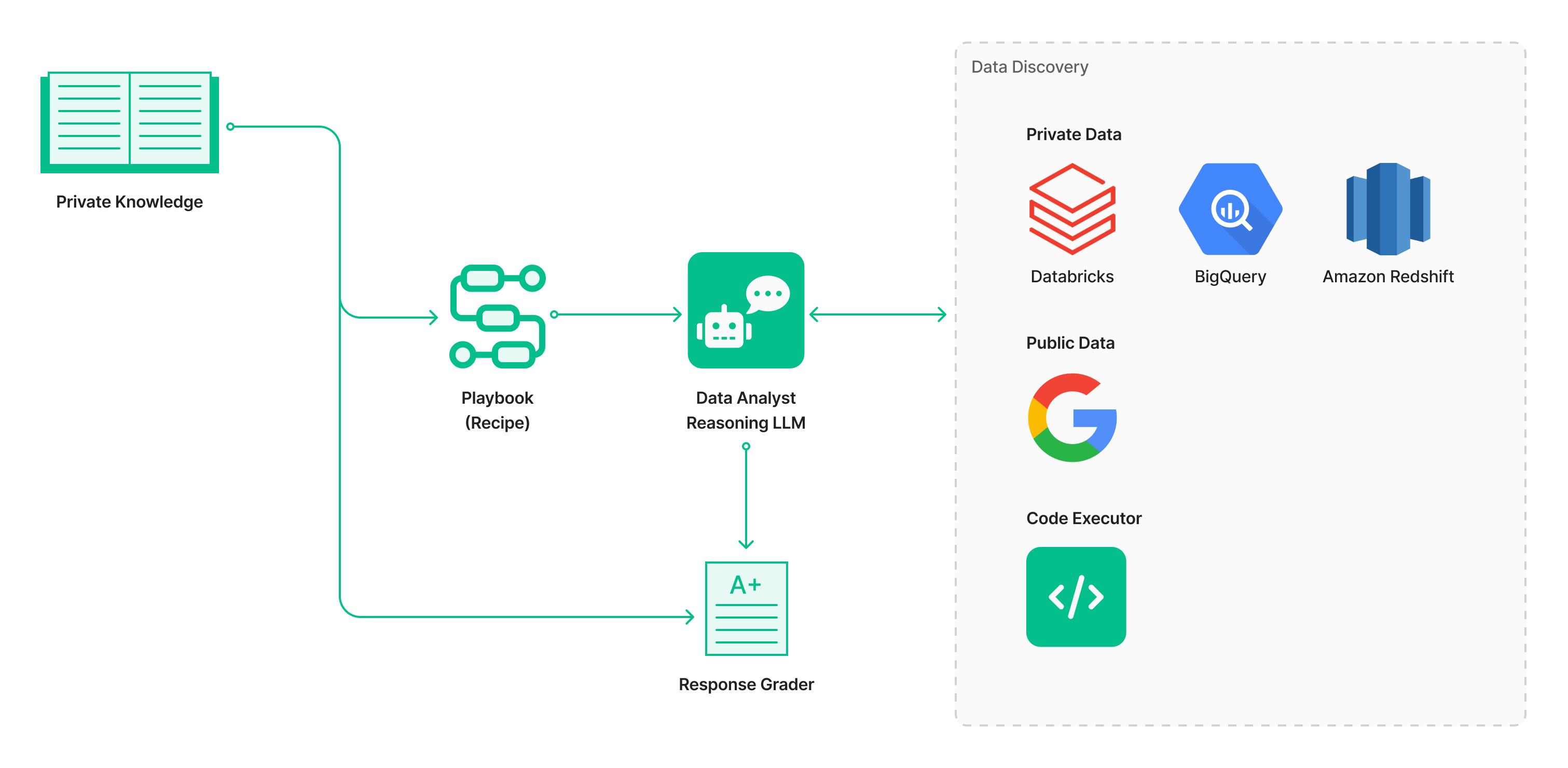
- พัฒนา Agent Framework และ Expert Playbooks
หนึ่งในหัวใจสำคัญคือการสร้าง Agent Framework ที่สามารถแปลงความรู้จากผู้เชี่ยวชาญให้กลายเป็นชุดแนวทางปฏิบัติ (Playbooks) ที่ Agent สามารถนำไปใช้งานได้จริง ซึ่งจะช่วยกำหนดแนวทางการวิเคราะห์ข้อมูลตามหลักของมนุษย์ และเป็นการใช้ความรู้จากผู้เชี่ยวชาญเป็นแกนหลักในการกำกับพฤติกรรมของ AI - รองรับการวิเคราะห์ข้อมูลจากหลายแหล่งข้อมูล
Agent ในอนาคตจะต้องสามารถวิเคราะห์ข้อมูลจากแหล่งที่หลากหลายได้อย่างไร้รอยต่อ ไม่ว่าจะเป็นข้อมูลภายใน (ที่อาจใช้งานผ่าน Natural Language Query หรือ NLQ Engine), ข้อมูลสาธารณะ, หรือแม้กระทั่งข้อมูลที่ต้องใช้การประมวลผลผ่านโค้ด ความสามารถนี้จะช่วยให้ Agent สามารถประยุกต์ใช้งานได้จริงในโลกที่ข้อมูลกระจัดกระจายและมีความหลากหลายสูง - สร้างระบบประเมินผลที่เข้มข้นและรอบด้าน
เพื่อตรวจสอบและพัฒนาให้ AI มีความแม่นยำยิ่งขึ้น จะมีการพัฒนาระบบประเมินผลที่ครอบคลุม โดยไม่จำกัดแค่เพียงอัตราการตอบถูกหรือคะแนน ELO เท่านั้น แต่จะรวมถึงการประเมินด้วยเกณฑ์ที่สะท้อนคุณภาพของผลลัพธ์จริง เช่น- อัตราการ Hallucination (ความคลาดเคลื่อนของข้อมูล)
- คะแนนด้าน Scalability
- คะแนนจากการทดสอบ (Test Score)
- คะแนนรวม (Overall Score)
โดยจะใช้แนวคิด “LLM เป็นผู้ตัดสิน” (Scoring by 'LLM as a Judge') ควบคู่ไปกับการประเมินซ้ำโดยผู้เชี่ยวชาญ เพื่อให้ได้การวิเคราะห์เชิงลึกที่สามารถใช้ปรับปรุงระบบได้ตรงจุด
- ทดสอบความสามารถในการทำงานของ AI เทียบกับมาตรฐานสากล
เพื่อยืนยันว่า Agent สามารถใช้งานได้กับหลากหลายบริบทและหลากหลายชุดข้อมูล การทดสอบจะต้องอ้างอิงจาก Global Benchmark ที่ได้รับการยอมรับ เช่น DABStep Leaderboard และ DA-bench Leaderboard
การประเมินจากภายนอกนี้จะเป็นตัวพิสูจน์ว่า Agent มีความแม่นยำ น่าเช่ือถือ และสามารถแข่งขันได้ในระดับนานาชาติ
ด้วยการพัฒนาทั้ง 4 ด้านนี้ งานในอนาคตมีเป้าหมายเพื่อสร้าง AI ที่สามารถวิเคราะห์ข้อมูลได้ในระดับผู้เชี่ยวชาญอย่างอัตโนมัติ มีระบบประเมินผลที่ละเอียด และผ่านการรับรองด้วยมาตรฐานระดับโลก ซึ่งจะเป็นการยกระดับขีดความสามารถของ AI ในการสร้างมุมมองเชิงลึกจากข้อมูลอย่างแท้จริง
สนใจร่วมเป็นส่วนหนึ่งกับ AI Labs ของเราได้ที่นี่