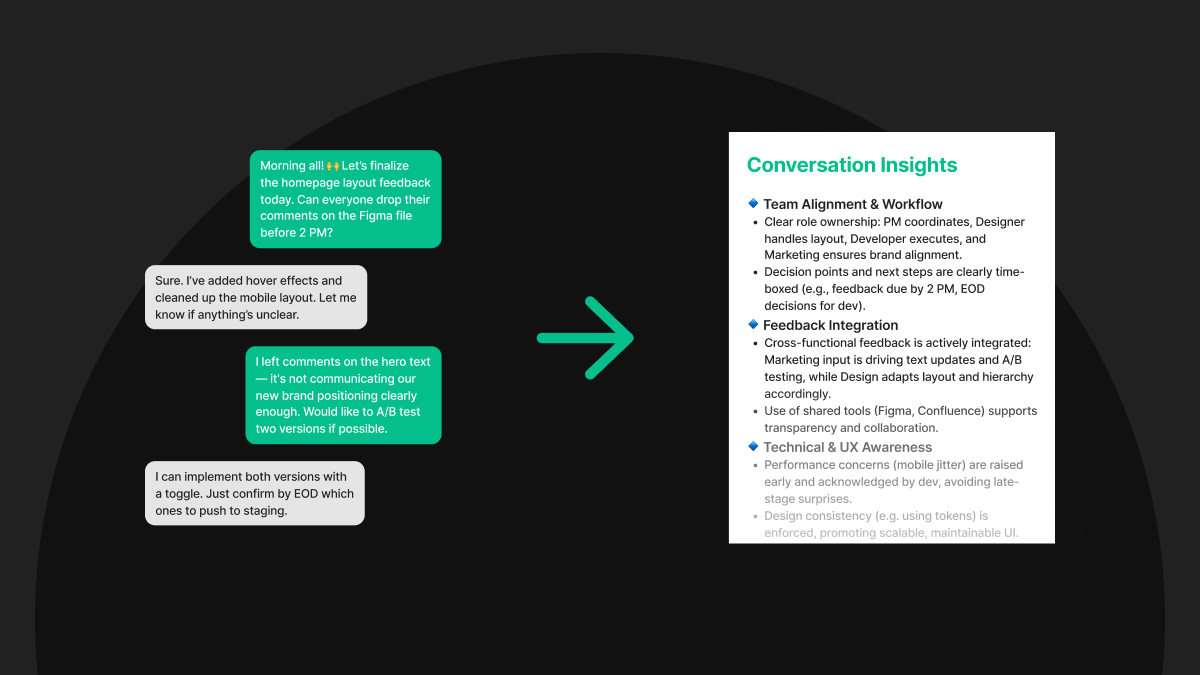

Call Analytics Agent: Unlocking Business Insights from Conversations at Scale
การเข้าใจบทสนทนาในปริมาณมากเป็นสิ่งจำเป็นในการพัฒนาประสบการณ์ลูกค้า ปรับปรุงการดำเนินงาน และค้นพบข้อมูลเชิงกลยุทธ์ที่สำคัญในทุกภาคส่วนของธุรกิจ
ในวงการวิเคราะห์การโทร ข้อมูลเสียงไม่ได้บอกแค่ประสิทธิภาพของเจ้าหน้าที่หรือความคิดเห็นเกี่ยวกับสินค้าเท่านั้น แต่ยังครอบคลุมบทสนทนาภายในและภายนอกที่หลากหลาย ตั้งแต่การสอบถามขอความช่วยเหลือ การติดต่อขาย ไปจนถึงการประสานงานและการสื่อสารในทีม อย่างไรก็ตาม เมื่อปริมาณการโทรเพิ่มขึ้น การวิเคราะห์ด้วยวิธีการใช้มนุษย์แบบเดิมจึงไม่เพียงพอ ทั้งในเรื่องความรวดเร็วและความสามารถในการขยายผล
เบื้องหลังผู้ช่วยวิเคราะห์การโทร: เปลี่ยนบทถอดเสียงให้กลายเป็นข้อมูลเชิงกลยุทธ์
เพื่อแก้ไขปัญหานี้ ผู้ช่วยวิเคราะห์การโทรที่ขับเคลื่อนด้วย AI ของเรา ถูกออกแบบมาเพื่อเพิ่มประสิทธิภาพและเร่งกระบวนการสร้างข้อมูลเชิงลึกจากบทถอดเสียงจำนวนมาก
เริ่มจากการแปลความข้อมูลบทสนทนาดิบ ระบุแนวคิดสำคัญ และร่างแนวทางการวิจัยจากธีมที่เกิดขึ้นใหม่ จากนั้นระบบจะสร้างคำค้นหาคีย์เวิร์ดเฉพาะเพื่อสำรวจคำถามธุรกิจในเชิงลึก เช่น การวิเคราะห์สาเหตุที่ทำให้ความรู้สึกของลูกค้าต่ำลง ยิ่งไปกว่านั้น ระบบนี้ยังช่วยสนับสนุนการตัดสินใจบนพื้นฐานข้อมูลในระดับที่ขยายผลได้อย่างมีประสิทธิภาพญ่ ทำให้ธุรกิจสามารถตอบสนองได้เร็วขึ้น มีประสิทธิภาพมากขึ้น และมั่นใจยิ่งขึ้น
กรอบการทำงานของผู้ช่วยวิเคราะห์การโทรด้วย AI
ต่อไปนี้เป็นคำอธิบายแต่ละขั้นตอนของกรอบการทำงานของตัวช่วยวิเคราะห์การโทรด้วย AI ตามที่แสดงในแผนภาพ:
.png)
โครงสร้างโดยรวม
ระบบประกอบด้วย 2 ส่วนหลักที่ทำงานร่วมกัน ได้แก่
- Eko (ชั้นของการโต้ตอบกับผู้ใช้)
- ให้บริการอยู่บน Azure และ Google Cloud
- ทำหน้าที่ในการโต้ตอบกับผู้ใช้ รับคำขอวิเคราะห์ผ่านแชต และส่งต่อเหตุการณ์ต่าง ๆ
- KM-Insight Engine
- ให้บริการอยู่บน Azure
- ทำงานประมวลผลแบบครบวงจร: ตั้งแต่บันทึกการโทร ถอดเสียง สรุปบทสนทนา สร้างเวกเตอร์ และดึงข้อมูลเชิงลึก
กระบวนการทำงานของ ETL สำหรับการบันทึกการโทรและระบบ KM-Insight Engine
ETL Call Recordings
1. การบันทึกการโทร
- การโทรด้วยเสียงจะถูกบันทึกและจัดเก็บเป็นไฟล์ .wav
2. การถอดเสียง (Transcription)
- ไฟล์ .wav ที่บันทึกไว้จะถูกส่งไปยังระบบแปลงเสียงเป็นข้อความ (STT - Speech-to-Text) เพื่อให้ได้บทถอดเสียงของการโทรฉบับเต็ม
3. การสรุปบทสนทนาและการส่งเหตุการณ์ (Summarization & Event Publishing)
- บทถอดเสียงจะถูกส่งผ่านตัวกลาง (Broker) ที่ทำหน้าที่กระจายข้อมูลไปยังแอปพลิเคชันผู้รับ (App Subscriber)
- จากนั้น App Subscriber จะเผยแพร่ "การสรุปข้อมูลเหตุการณ์แบบครบถ้วน" (Complete Summarization Event)
KM-Insight Engine
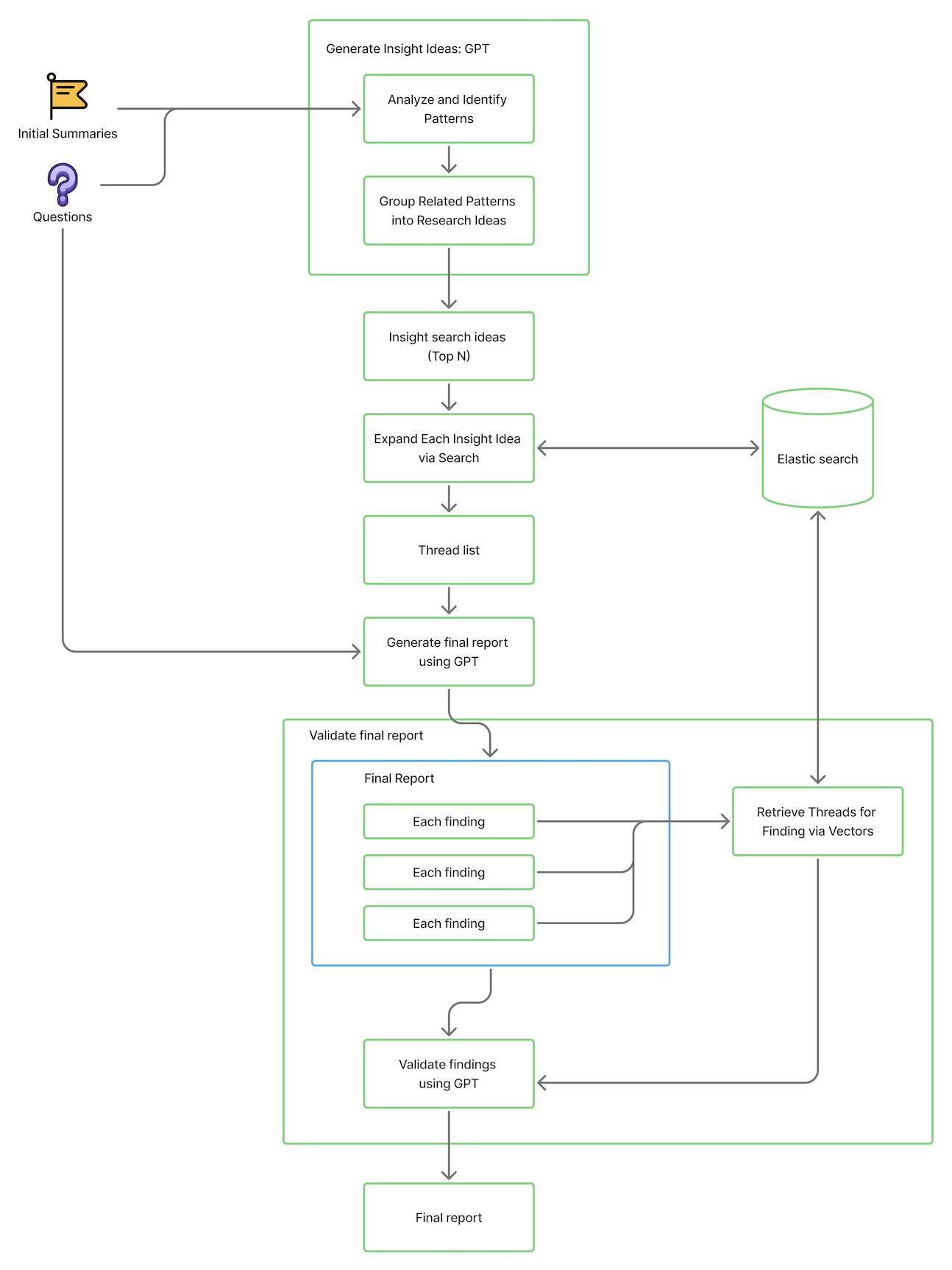
KM-Insight ถูกออกแบบมาเพื่อเปลี่ยนคำถามของผู้ใช้อย่างเป็นระบบให้กลายเป็นรายงานที่ครอบคลุมและมีหลักฐานรองรับอย่างชัดเจน
กระบวนการเริ่มจากการดึงสรุปเนื้อหาที่เกี่ยวข้องจากดัชนีค้นหา (search index) จากนั้นใช้ GPT เพื่อสร้างแนวคิดวิจัยเชิงลึกจากสรุปเหล่านั้น แต่ละแนวคิดจะถูกขยายต่อด้วยการค้นหาแบบเวกเตอร์ (vector search) เพื่อหาข้อมูลสนับสนุนในเชิงลึก เมื่อได้ข้อมูลครบถ้วน ระบบจะสังเคราะห์เนื้อหาออกมาเป็นรายงานที่มีโครงสร้างชัดเจน ประกอบด้วย บทนำ ข้อค้นพบ และข้อเสนอแนะ สุดท้าย ระบบจะตรวจสอบความน่าเชื่อถือของแต่ละข้อค้นพบ โดยวิเคราะห์เนื้อหาที่เกี่ยวข้อง เพื่อให้มั่นใจว่าข้อมูลที่ได้นั้นถูกต้องและมีหลักฐานรองรับอย่างชัดเจน
เครื่องมือ
- GPT: o4-mini
- Elastic search
กระบวนการทำงาน (Flow)
ขั้นตอนที่ 1: ดึงสรุปข้อมูลเบื้องต้น
ดึงรหัสเอกสารและสรุปเนื้อหาจาก OpenSearch โดยอิงจากคำถามวิจัยและตัวกรองต่าง ๆ เพื่อรวบรวมชุดข้อมูลที่เกี่ยวข้องสำหรับการวิเคราะห์
ขั้นตอนที่ 2: GPT - สร้างแนวคิดเชิงลึก
GPT จะใช้ข้อมูลสรุปที่ได้ เพื่อสร้างแนวคิดวิจัยเชิงลึก โดยแต่ละแนวคิดจะมีชื่อเรื่อง คีย์เวิร์ดที่เกี่ยวข้อง และตัวอย่างเนื้อหาที่สะท้อนธีมหลักของข้อมูล
ขั้นตอนที่ 3: ขยายแนวคิดเชิงลึกผ่านการค้นหา
สำหรับแต่ละแนวคิดเชิงลึก ระบบจะทำการค้นหาแบบเวกเตอร์โดยใช้คีย์เวิร์ดและชื่อเรื่อง เพื่อค้นหาข้อความหรือบทสนทนาฉบับเต็มที่เกี่ยวข้อง ขั้นตอนนี้ช่วยขยายชุดข้อมูลจากแค่สรุปเนื้อหา ไปสู่เนื้อหาที่ลึกและละเอียดมากขึ้น เพื่อรองรับการวิเคราะห์ในเชิงลึกได้ดียิ่งขึ้น
ขั้นตอนที่ 4: GPT - สรุปเป็นรายงานฉบับสมบูรณ์
GPT จะสังเคราะห์ข้อมูลทั้งหมดที่ได้มาจากขั้นตอนก่อนหน้าให้กลายเป็นรายงานที่ครอบคลุม ประกอบด้วย บทนำ ข้อค้นพบโดยละเอียด ข้อเสนอแนะที่นำไปใช้ได้จริง และคำตอบต่อคำถามวิจัย
ขั้นตอนที่ 5: วิเคราะห์ข้อค้นพบแต่ละประเด็น
แต่ละข้อค้นพบจะถูกตรวจสอบเพิ่มเติม โดยดึงข้อมูลหรือข้อความสนับสนุนเพิ่มเติม เพื่อยืนยันว่าแต่ละประเด็นมีหลักฐานเพียงพอ
ขั้นตอนที่ 6: GPT - ตรวจสอบความถูกต้องของข้อมูลสนับสนุน
GPT จะประเมินความเกี่ยวข้องและความน่าเชื่อถือของข้อมูลสนับสนุน เพื่อยืนยันว่าแต่ละข้อความหรือบทสนทนานั้นสนับสนุนข้อค้นพบได้จริง
การประเมินผลลัพธ์ของ KM-Insight
เพื่อประเมินว่า KM-Insight สามารถสร้างข้อมูลเชิงลึกคุณภาพสูงและวิเคราะห์ข้อมูลได้ในระดับที่เทียบเท่ากับนักวิเคราะห์ที่เป็นมนุษย์หรือไม่ เราได้ดำเนินกระบวนการประเมินแบบสองชั้น (Dual-Evaluation Process) โดยเปรียบเทียบผลลัพธ์ที่ได้จาก KM-Insight กับผลลัพธ์ที่ได้จากมนุษย์ภายใต้คำถามวิจัยเดียวกัน
คำตอบจากทั้งสองฝั่งถูกประเมินด้วยเกณฑ์เดียวกันในหลากหลายมิติที่สำคัญ ได้แก่ ความเข้าใจในคำร้องขอ, ความลึกซึ้งของการวิเคราะห์, และคุณภาพของคำแนะนำ
ผลลัพธ์จากการประเมินนี้แสดงให้เห็นถึงความสอดคล้องกันอย่างมากระหว่างการประเมินโดย AI และมนุษย์ โดยมีคะแนนเฉลี่ยต่างกันเพียง 0.3 คะแนนเท่านั้น (ดูภาคผนวก A) ซึ่งช่องว่างเพียงเล็กน้อยนี้ชี้ให้เห็นว่า การประเมินที่ขับเคลื่อนด้วย AI มีศักยภาพและความน่าเชื่อถือสูง จึงถือเป็นวิธีการที่เหมาะสมในการใช้ประเมินประสิทธิภาพของ KM-Insight
ด้วยเหตุนี้ การประเมินผลลัพธ์จาก KM-Insight ในบทความนี้จะรายงานโดยอิงจากคะแนนที่ประเมินโดย AI
วัตถุประสงค์
วัตถุประสงค์ของการประเมินนี้คือเพื่อพิจารณาว่า KM-Insight สามารถดำเนินการสร้างข้อมูลเชิงลึกและวิเคราะห์ข้อมูลได้อย่างมีประสิทธิภาพ ในระดับที่เทียบเคียงกับนักวิเคราะห์ข้อมูลที่เป็นมนุษย์หรือไม่ โดยการเปรียบเทียบผลลัพธ์ที่ได้จาก KM-Insight กับผลลัพธ์ที่ได้จากมนุษย์ ซึ่งใช้คำถามวิจัยและเกณฑ์การประเมินเดียวกัน เราตั้งเป้าที่จะประเมินความสามารถของระบบในการทำความเข้าใจปัญหาทางธุรกิจ วิเคราะห์ข้อมูลอย่างมีความหมาย และให้ข้อมูลเชิงลึกที่มีคุณค่า
เกณฑ์การประเมิน (Evaluation Criteria)
- ความเข้าใจและการตอบโจทย์ (Understanding and Addressing the Request)
ประเมินว่าผลลัพธ์สามารถตีความและตอบสนองต่อวัตถุประสงค์ของงานวิจัยได้ดีเพียงใด
- 1 (แย่) - ไม่เข้าใจโจทย์เลย และคำตอบไม่ตรงกับสิ่งที่ขอ
- 2 (พอใช้) - พอเข้าใจโจทย์แต่ยังพลาดประเด็นสำคัญ หรือเข้าใจเป้าหมายหลักผิด
- 3 (ดี) - ตอบโจทย์หลักได้ แต่ยังขาดความลึก ความแม่นยำ หรือความต่อเนื่องบางจุด
- 4 (ดีมาก) - ครอบคลุมครบเกือบทั้งหมด อาจมีบางจุดที่ขาดหรือคลุมเครือเล็กน้อย
- 5 (ดีเยี่ยม) - แสดงความเข้าใจลึกซึ้งระดับผู้เชี่ยวชาญ ครอบคลุมทุกประเด็น พร้อมคาดการณ์กรณีพิเศษได้ด้วย
- การวิเคราะห์และข้อค้นพบ (Analysis and Findings)
วัดความลึก ความถูกต้อง และความคิดสร้างสรรค์ของข้อค้นพบ พร้อมหลักฐานสนับสนุน
- 1 (แย่) - ข้อค้นพบผิด ไม่มีหลักฐาน หรือไม่ปรากฏข้อค้นพบเลย
- 2 (พอใช้) - มีข้อค้นพบแต่หลักฐานอ่อน เป็นเพียงคำบรรยายทั่วไป ขาดน้ำหนัก
- 3 (ดี) - ข้อค้นพบถูกต้อง มีหลักฐานรองรับ แต่ยังไม่ลึกหรือครอบคลุม
- 4 (ดีมาก) - ข้อค้นพบมีความลึก เชื่อมโยงกับข้อมูลจริง หลักฐานแข็งแรง ขาดเล็กน้อยเท่านั้น
- 5 (ดีเยี่ยม) - ข้อค้นบน่าสนใจ ไม่ธรรมดา มีหลักฐานแน่นหนา และช่วยให้เข้าใจประเด็นได้ลึกยิ่งขึ้น
- ข้อเสนอแนะ (Recommendations)
ประเมินว่าข้อเสนอแนะที่ให้มานั้นมีความเกี่ยวข้อง ใช้ได้จริง และเชื่อมโยงกับข้อค้นพบหรือไม่
- 1 (แย่) - ไม่มีข้อเสนอแนะ หรือข้อเสนอที่ให้มานำไปใช้ไม่ได้หรือไม่เกี่ยวข้อง
- 2 (พอใช้) - มีข้อเสนอแนะ แต่คลุมเครือ ทั่วไป หรือไม่สามารถนำไปปฏิบัติจริงได้
- 3 (ดี) - ข้อเสนอแนะสามารถนำไปใช้ได้และสอดคล้องกับข้อสรุป แต่ยังขาดความเฉพาะเจาะจง ลำดับความสำคัญ หรือผลกระทบที่ชัดเจน
- 4 (ดีมาก) - ข้อเสนอแนะชัดเจน ปฏิบัติได้จริง มีลำดับความสำคัญ พร้อมเชื่อมโยงกับผลกระทบทางธุรกิจ
- 5 (ดีเยี่ยม) - ข้อเสนอเชิงกลยุทธ์ มีข้อมูลรองรับ นำไปใช้ได้ทันที และเชื่อมโยงกับปัจจัยขับเคลื่อนหลักและข้อจำกัดขององค์กรอย่างชัดเจน
ผลลัพธ์
ในบริบทของบริษัทที่ดำเนินธุรกิจด้านการวิเคราะห์ข้อมูลจากการสนทนา (Call Analytics) มีการวิเคราะห์ชุดข้อมูลบันทึกบทสนทนาขนาดใหญ่ ซึ่งครอบคลุมทั้งการขาย การบริการลูกค้า และการสื่อสารภายในองค์กร เป้าหมายคือการดึงข้อมูลเชิงลึกที่มีความหมายจากบทสนทนาเหล่านี้เพื่อตอบคำถามทางธุรกิจที่เฉพาะเจาะจง โดย KM-Insight ทำหน้าที่สร้างรายงานจากข้อมูลดังกล่าว
ผลการประเมินที่แสดงด้านล่างเป็นการเปรียบเทียบประสิทธิภาพของ KM-Insight กับนักวิเคราะห์ที่เป็นมนุษย์ โดยใช้ระบบให้คะแนนที่ขับเคลื่อนด้วย AI เพื่อประเมินคุณภาพของข้อมูลเชิงลึกที่ได้
.png)
การประเมินนี้เปรียบเทียบประสิทธิภาพของ KM-Insight กับนักวิเคราะห์ข้อมูลในระดับประสบการณ์ที่แตกต่างกัน โดยผู้เข้าร่วมทุกคนตอบคำถามวิจัยชุดเดียวกัน และคำตอบทั้งหมดถูกประเมินด้วยเกณฑ์ที่สม่ำเสมอ
ผลการประเมินแสดงให้เห็นว่า KM-Insight ของเรา มีประสิทธิภาพในระดับที่ใกล้เคียงกับนักวิเคราะห์ข้อมูลระดับผู้เชี่ยวชาญ (Expert) และสามารถเอาชนะนักวิเคราะห์ระดับต้น (Junior) และระดับกลาง (Intermediate) ได้อย่างมีนัยสำคัญ แม้ว่านักวิเคราะห์ระดับผู้เชี่ยวชาญจะได้คะแนนสูงที่สุด แต่ประสิทธิภาพของ KM-Insight ก็อยู่ในระดับที่ใกล้เคียงกัน โดยมีคะแนนเฉลี่ยแตกต่างกันเพียง 0.11 คะแนน ซึ่งสะท้อนถึงความสามารถของระบบในการให้ข้อมูลเชิงลึกและการวิเคราะห์ที่มีคุณภาพ ลึกซึ้ง และมีความเกี่ยวข้องในระดับที่ใกล้เคียงกับผู้เชี่ยวชาญที่มีประสบการณ์
ประโยชน์
- การจัดการข้อมูลที่ขยายผลได้
ด้วยการใช้ OpenSearch และการค้นหาแบบเวกเตอร์ (KNN) ระบบสามารถจัดการและดึงข้อมูลจากเอกสารนับพันได้อย่างรวดเร็วและมีประสิทธิภาพ เหมาะสำหรับฐานความรู้ขนาดใหญ่
- การสร้างข้อมูลเชิงลึกด้วย AI
ระบบใช้ GPT ในหลายขั้นตอน เช่น การสร้างไอเดีย การเขียนสรุป และการตรวจสอบหลักฐาน ทำให้ได้การวิเคราะห์ที่มีความหมายและคล้ายการวิเคราะห์ของมนุษย์ ซึ่งถ้าทำเองจะใช้เวลานาน - ข้อค้นพบที่มีหลักฐานสนับสนุน
ข้อมูลเชิงลึกและคำแนะนำทุกอย่างจะมีเอกสารอ้างอิงจริง และได้รับการตรวจสอบโดย GPT เพื่อให้มั่นใจว่าข้อค้นพบมีความเกี่ยวข้อง ถูกต้อง และอธิบายได้ - ประหยัดเวลาและแรงงาน
การทำงานอัตโนมัติในการวิเคราะห์เอกสาร การสกัดข้อมูลเชิงลึก และการเขียนรายงาน ช่วยลดงานที่ต้องทำโดยใช้มนุษย์อย่างมากในกระบวนการวิจัยหรือการตรวจสอบ - การสนับสนุนการตัดสินใจที่ดีขึ้น
ผลลัพธ์สุดท้ายไม่เพียงแต่มีข้อค้นพบ แต่ยังรวมถึงคำแนะนำที่ปฏิบัติได้จริง และคำตอบตรงประเด็นสำหรับคำถามวิจัย ช่วยให้ผู้ตัดสินใจเข้าใจและลงมือทำได้เร็วขึ้น
ภาคผนวก A
การเปรียบเทียบประสิทธิภาพของผู้ให้คะแนน
เพื่อประเมินความน่าเชื่อถือและคุณภาพของผลลัพธ์จาก KM-Insight เราได้ใช้กระบวนการประเมินผลแบบคู่ (dual-evaluation process) ซึ่งทั้งผู้ประเมินมนุษย์และโมเดล AI (GPT: o3) ได้ให้คะแนนชุดของคำตอบการวิจัยที่สร้างโดย KM-Insight ทั้งหมด การประเมินทั้งหมดได้ดำเนินการโดยใช้ชุดเกณฑ์การให้คะแนนที่ใช้ร่วมกันในสามมิติหลัก:
- การเข้าใจและการตอบสนองต่อคำขอ
- การวิเคราะห์และผลการค้นพบ
- คำแนะนำ
วัตถุประสงค์
เป้าหมายหลักของกระบวนการนี้คือการประเมินว่า การประเมินของ AI ตรงกับการประเมินของผู้ประเมินมนุษย์มากน้อยเพียงใด และเพื่อกำหนดว่า AI สามารถประเมินคุณภาพของผลลัพธ์จาก KM-Insight ได้อย่างอิสระและสม่ำเสมอหรือไม่ การทำให้การประเมินตรงกันนี้จะช่วยยืนยันการใช้การให้คะแนนโดย AI เป็นวิธีการที่เชื่อถือได้สำหรับการประเมินผลอัตโนมัติ
กระบวนการให้คะแนน (Scoring Process)
- ทั้งผู้เชี่ยวชาญที่เป็นมนุษย์และโมเดล AI จะทำการประเมินผลลัพธ์จาก KM-Insight โดยใช้เกณฑ์การให้คะแนนแบบเดียวกัน (ระดับ 1–5) ภายใต้หัวข้อการประเมินที่กำหนดไว้
- ผู้ประเมินที่เป็นมนุษย์ ให้คะแนนตามความเชี่ยวชาญในสาขานั้น ๆ และใช้วิจารณญาณตามบริบท
- AI ได้รับคำสั่งผ่าน prompt ให้ใช้เกณฑ์การให้คะแนนเดียวกัน พร้อมอธิบายเหตุผลประกอบการให้คะแนนแต่ละข้อ
- ผลการให้คะแนนจากทั้งสองฝ่ายจะถูกนำมาเปรียบเทียบเพื่อดูว่า:
- คะแนนมีความใกล้เคียงหรือ สอดคล้องกันแค่ไหน
- เหตุผลในการให้คะแนนมีความเสถียรและสอดคล้องในเชิงตรรกะหรือไม่
- AI สามารถประเมินคุณภาพของ insight ได้อย่างน่าเชื่อถือ คล้ายกับผู้ประเมินที่เป็นมนุษย์หรือไม่
ผลลัพธ์
ประสิทธิภาพการให้คะแนนของผู้ประเมิน AI (โมเดล GPT o3) ถูกเปรียบเทียบกับผู้ให้คะแนนมนุษย์ในตัวอย่างคำถาม 5 ข้อ คะแนนสำหรับตัวอย่างคำถามแต่ละข้อแสดงในกราฟและตารางด้านล่างนี้:
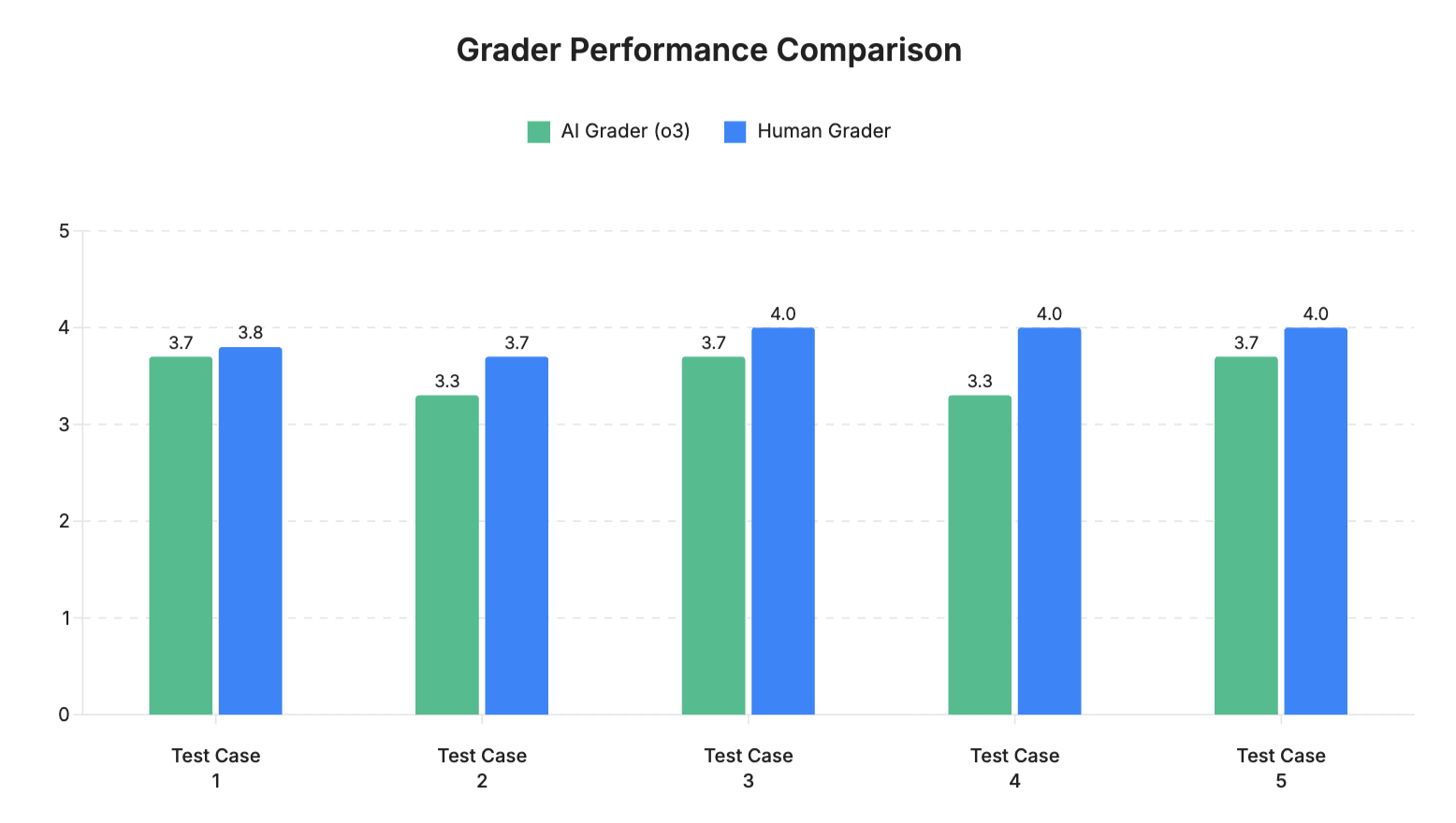
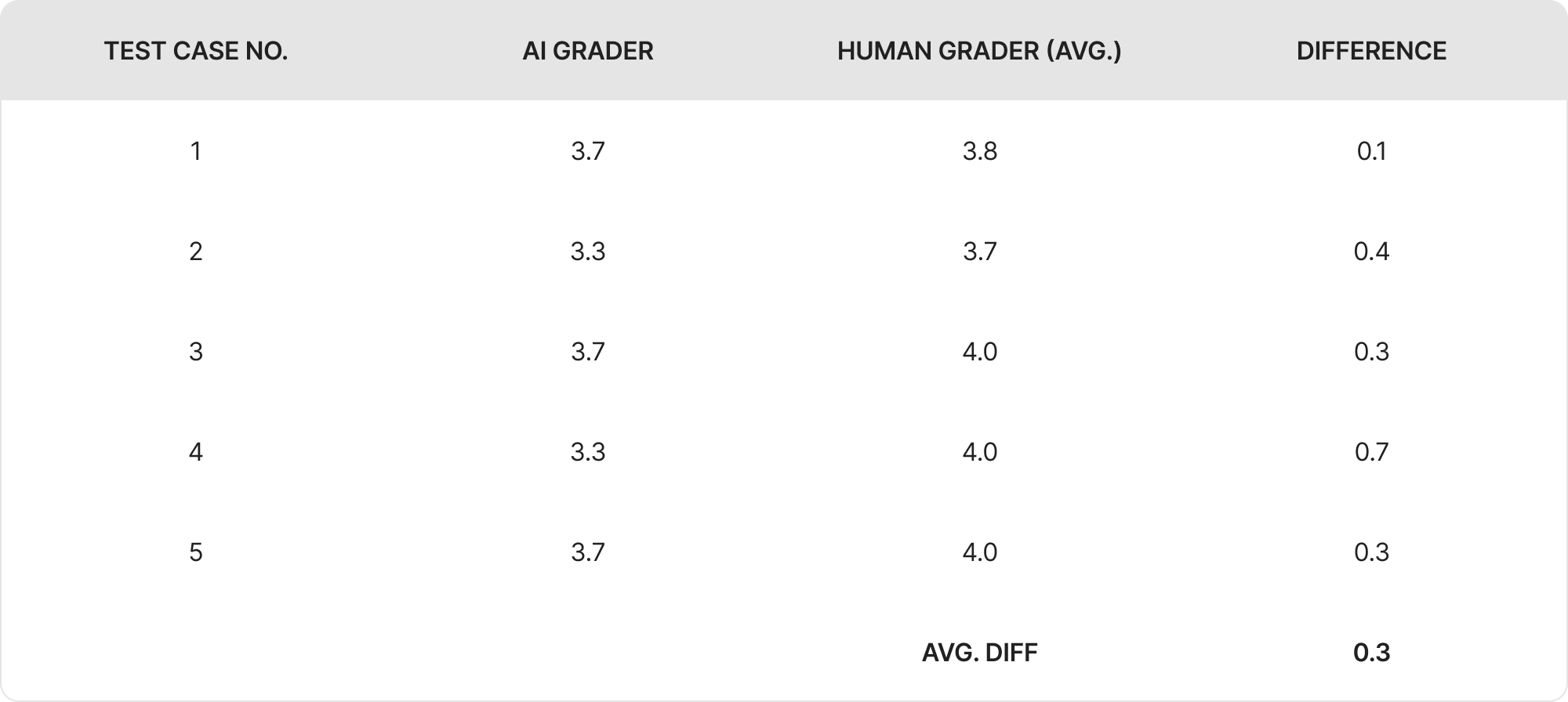
สรุปผลการให้คะแนน (Grading Results Summary)
จากผลลัพธ์ที่ถูกประเมินทั้ง 5 ข้อ พบว่า AI ที่ใช้ในการให้คะแนนมีระดับความสอดคล้องกับผู้ประเมินที่เป็นมนุษย์ในระดับสูง โดยมีความแตกต่างของคะแนนเพียงเล็กน้อยเท่านั้น ค่าความแตกต่างเฉลี่ยอยู่ที่ 0.3 คะแนน ซึ่งแสดงให้เห็นว่า AI สามารถประเมินผลได้สอดคล้องกับวิจารณญาณของมนุษย์ในภาพรวม
- โดยส่วนใหญ่แล้ว AI มักจะให้คะแนนต่ำกว่ามนุษย์เล็กน้อย
- ความแตกต่างของคะแนนที่มากที่สุดอยู่ที่ 0.7 คะแนน และน้อยที่สุดคือ 0.1 คะแนน
- โดยรวมแล้ว AI แสดงให้เห็นถึงความสามารถในการให้คะแนนอย่างน่าเชื่อถือ ซึ่งชี้ให้เห็นถึงศักยภาพในการช่วยสนับสนุน หรือแม้แต่ทำให้บางส่วนของกระบวนการประเมินเป็นแบบอัตโนมัติได้
สนใจร่วมเป็นส่วนหนึ่งกับ AI Labs ของเราได้ที่นี่