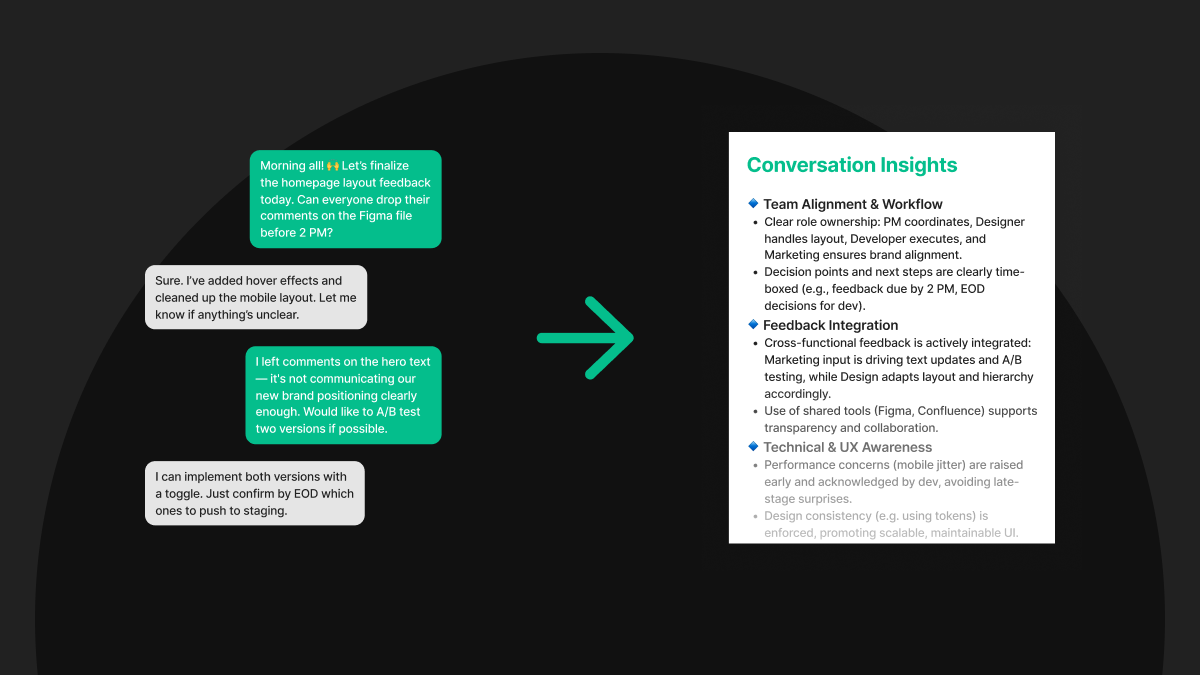

Turn Call Transcripts into Strategic Insights with KM-Insight’s AI Analytics
Why Scalable Conversation Analysis is the Next Frontier in Business Intelligence
Understanding conversations at scale is essential for improving customer experience, optimizing operations, and uncovering strategic insights across the business. In the call analytics industry, voice data reveals more than just agent performance or product feedback, it spans a wide range of internal and external conversations, from support inquiries and sales interactions to operational coordination and team communication. However, as call volumes increase, traditional manual analysis falls short, lacking both speed and scalability.
Inside the Call Analytics Agent: Turning Transcripts into Strategic Insights
To address this, our AI-powered call analytics agent is designed to enhance and accelerate insight generation across large sets of call transcripts. It starts by interpreting raw conversation data, identifying key ideas, and drafting research directions based on emerging themes. From there, it formulates targeted keyword queries to explore deeper business questions—for example, understanding the cause behind a drop in customer sentiment. More than just automation, this system enables data-driven decision-making at scale, empowering businesses to respond faster, smarter, and with greater confidence.
AI Call-Analytics Agent Framework
Here is a step-by-step explanation of the AI Call-Analytics Agent Framework as shown in the architecture diagram:
.png)
Overall Structure
The system operates across two main environments:
- Eko (User Interaction Layer)
- Hosted on Azure + Google Cloud
- Responsible for user interaction, chat-based insight requests, and event forwarding
- KM-Insight Engine
- Hosted on Azure
- Performs the full pipeline: call recording, transcription, summarization, embedding, and insight extraction
Process Flow for ETL Call Recordings and KM-Insight Engine
ETL Call recordings
1. Call Recording
- A voice call is recorded and stored as a .wav file.
2. Transcription
- The recorded .wav file is sent to the STT (Speech-to-Text) to get a full text transcription of the call.
3. Summarization & Event Publishing
- The transcription is passed through a Broker, which distributes it to an App Subscriber.
- The App Subscriber publishes a Complete Summarization Event containing.
KM-insight Engine
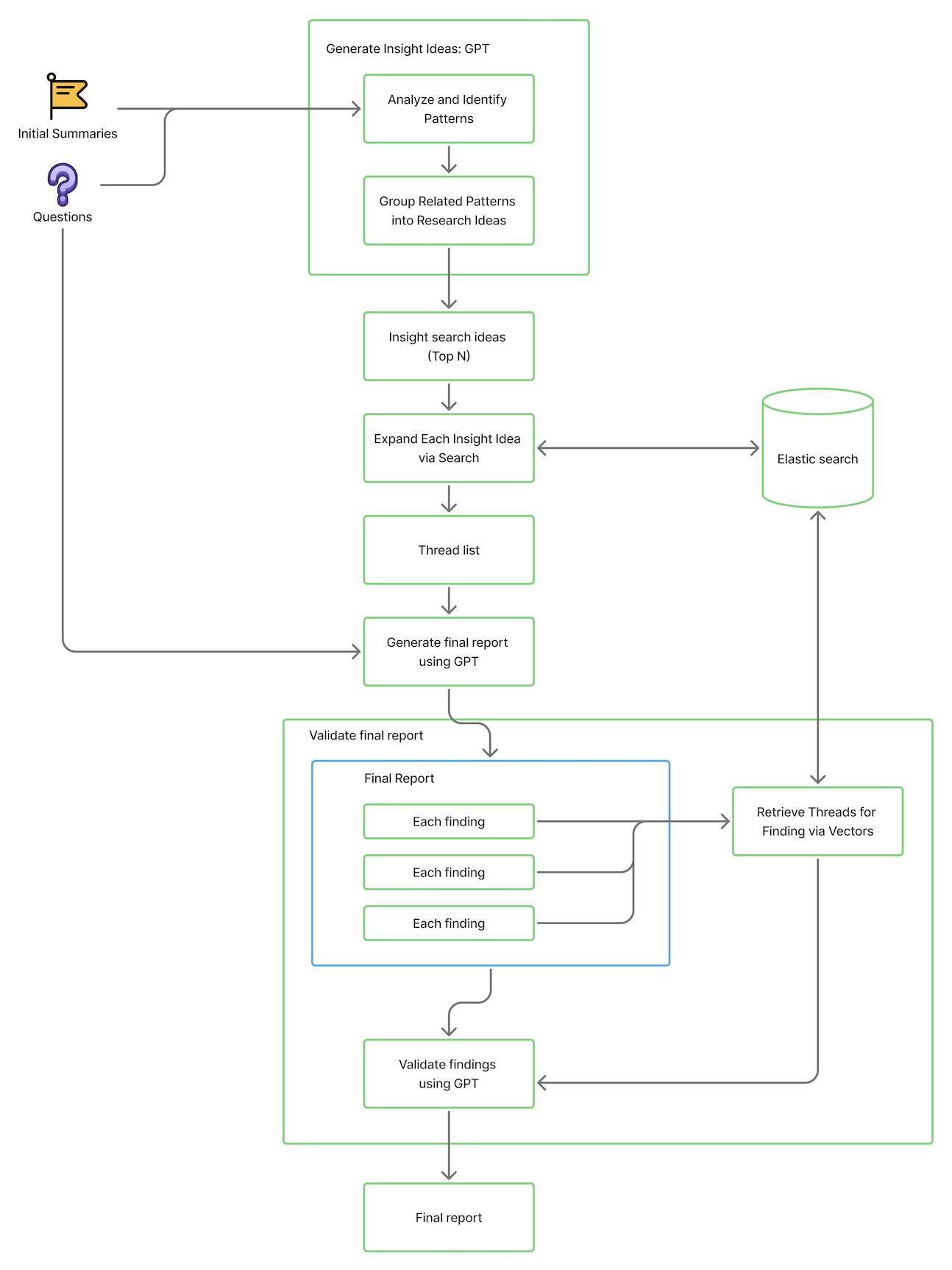
KM-insight is designed to systematically transform a user’s research question into a comprehensive, evidence-backed report. It begins by retrieving relevant document summaries from a search index, then leverages GPT to generate insightful research ideas based on those summaries. Each idea is further expanded through advanced vector searches to uncover detailed supporting threads. The engine then synthesizes these findings into a structured report containing introductions, finding, and recommendations. Finally, it validates each finding by analyzing related content for relevance and evidence strength, ensuring that the final insights are both accurate and well-supported.
Here is the workflow diagram of the KM-Insight engine:
Tools
- GPT: o4-mini
- Elastic search
Flow
Step 1: Fetch Initial Summaries
Retrieve document IDs and content summaries from OpenSearch based on the research question and filters. This provides a focused set of relevant data to begin analysis.
Step 2: GPT - Generate Insight Ideas
Using the summaries, GPT generates insightful research ideas. Each idea includes a title, relevant keywords, and sample content that highlight key themes.
Step 3: Expand Insight Ideas via Search
For each insight idea, perform vector-based searches using keywords and titles to find related full threads. This expands the dataset beyond summaries to richer, detailed content for deeper analysis.
Step 4: GPT - Generate Final Summary Report
GPT compiles the expanded data into a comprehensive report, including an introduction, detailed findings, actionable recommendations, and a direct answer to the research question.
Step 5: Analyze Each Finding
Each finding is further examined by fetching additional supporting threads. This ensures findings are backed by sufficient evidence.
Step 6: Validate Finding Threads via GPT
GPT assesses the relevance and strength of evidence in the supporting threads, confirming which threads truly support each finding.
Evaluation of KM-Insight Results
To assess whether KM-Insight can generate high-quality insights and perform data analysis on par with human analysts, we implemented a dual-evaluation process. This involved comparing outputs from KM-Insight with those produced by humans for the same research questions. Both sets of responses were evaluated using the same grading criteria across key dimensions, including understanding of the request, analytical depth, and quality of recommendations.
The results of this evaluation show a strong alignment between AI and human assessments, with an average score difference of only 0.3 points (see Appendix A). Based on this minimal gap, we conclude that AI-based grading demonstrates strong potential and reliability, making it a viable method for evaluating KM-Insight’s performance.
As a result, the evaluation of KM-Insight outputs will be presented using AI-generated scores.
Purpose
The goal of this evaluation is to determine whether KM-Insight can effectively perform insight generation and data analysis tasks at a level comparable to human analysts. By comparing KM-Insight’s outputs with those produced by humans, using the same research questions and evaluation criteria, we aim to assess the system’s capability to understand business problems, analyze data meaningfully, and provide valuable insights.
Evaluation Criteria
- Understanding and Addressing the Request
Evaluates how well the response interprets and fulfills the research objective.- 1 (Poor) - Misses the point entirely; response does not align with the original request.
- 2 (Fair) - Shows some recognition of the task but misses major elements or misinterprets core goals.
- 3 (Good) - Covers main asks but the coverage, depth, or precision is limited or inconsistent.
- 4 (Very Good) - Fully addresses all parts of the request with only minor omissions or ambiguities.
- 5 (Excellent) - Demonstrates expert-level understanding, anticipates edge cases, and thoroughly answers every facet of the request.
- Analysis and Findings
Measures the depth, accuracy, and originality of insights, and how well they’re supported by evidence.- 1 (Poor) - Findings are incorrect, unsupported, or entirely missing.
- 2 (Fair) - Provides limited evidence or mostly descriptive results; key insights are weak or questionable.
- 3 (Good) - Findings are mostly accurate and evidence-based, but lack depth or completeness.
- 4 (Very Good) - Insightful, data-driven findings with strong supporting evidence; minor gaps only.
- 5 (Excellent) - Compelling, non-obvious, and well-substantiated insights that materially advance understanding.
- Recommendations
Evaluates whether the proposed actions are relevant, feasible, and tied to the findings.- 1 (Poor) - No recommendations provided, or those given are unusable or unrelated to the findings.
- 2 (Fair) - Recommendations exist but are vague, generic, or impractical.
- 3 (Good) - Actionable recommendations that follow logically from conclusions; may lack specificity, prioritization, or impact clarity.
- 4 (Very Good) - Clear, feasible, and prioritized recommendations; connections to business impact are discussed.
- 5 (Excellent) - Highly strategic, quantified, and immediately actionable recommendations, tightly tied to core drivers and operational constraints.
Results
In the context of a call analytics company, a large collection of call transcripts, covering sales, customer support, and internal employee communications, is analyzed. The goal is to extract meaningful insights from these conversations to answer specific business questions. The KM-Insight engine generates reports based on this data.The results below compare KM-Insight's performance with human analysts, using scores assigned by an AI-based grading system to evaluate the quality of insights.
.png)
The evaluation compared KM-Insight's performance with that of human analysts at different experience levels. Each participant answered the same set of research questions, and their responses were graded using a consistent rubric. These results indicate that KM-Insight performs at a level comparable to an expert data analyst, significantly outperforming both junior and intermediate analysts. While the expert analyst achieved the highest score, the KM-Insight engine’s performance closely follows, with only a 0.11-point difference, demonstrating its ability to deliver high-quality insights and analysis with a level of depth and relevance similar to that of experienced professionals.
Benefits
- Scalable Data Handling
By integrating OpenSearch and vector search (KNN), the engine can process and retrieve thousands of documents efficiently, making it suitable for large knowledge bases.
- AI-Powered Insight Generation
Using GPT at multiple stages (idea generation, summary writing, and evidence validation) allows the engine to produce meaningful, human-like analysis that would be time-consuming to do manually.
- Evidence-Backed Findings
Each insight and recommendation is supported by real document threads. These are validated by GPT to ensure that the findings are relevant, grounded, and explainable.
- Saves Time and Effort
The automation of document analysis, insight extraction, and report writing significantly reduces the manual work involved in traditional research or auditing processes.
- Improved Decision Support
The final output includes not just findings, but also actionable recommendations and a direct answer to the research question—helping decision-makers quickly understand and act on insights.
Appendix A
Grader Performance Comparison
To assess the reliability and quality of KM-Insight engine outputs, we implemented a dual-evaluation process in which both human evaluators and an AI model (GPT: o3) graded the same set of KM-Insight–generated research responses. All evaluations were conducted using a shared set of grading criteria across three key dimensions:
- Understanding and Addressing the Request
- Analysis and Findings
- Recommendations
Purpose
The primary goal of this process is to evaluate how closely the AI’s assessments align with those of human evaluators, and to determine whether the AI can independently and consistently assess the quality of KM-Insight’s outputs. This alignment would validate the use of AI-based scoring as a reliable method for automated evaluation.
Scoring Process
- Both human experts and the AI model evaluate the same KM-Insight output using a shared 1–5 scoring rubric across those criteria.
- Humans provide scores based on domain expertise and contextual judgment.
- AI is prompted with the same rubric and generates scores with justifications.
- The results are compared to measure alignment in scoring, consistency in reasoning, and to assess whether AI can reliably evaluate insight quality like a human reviewer.
Results
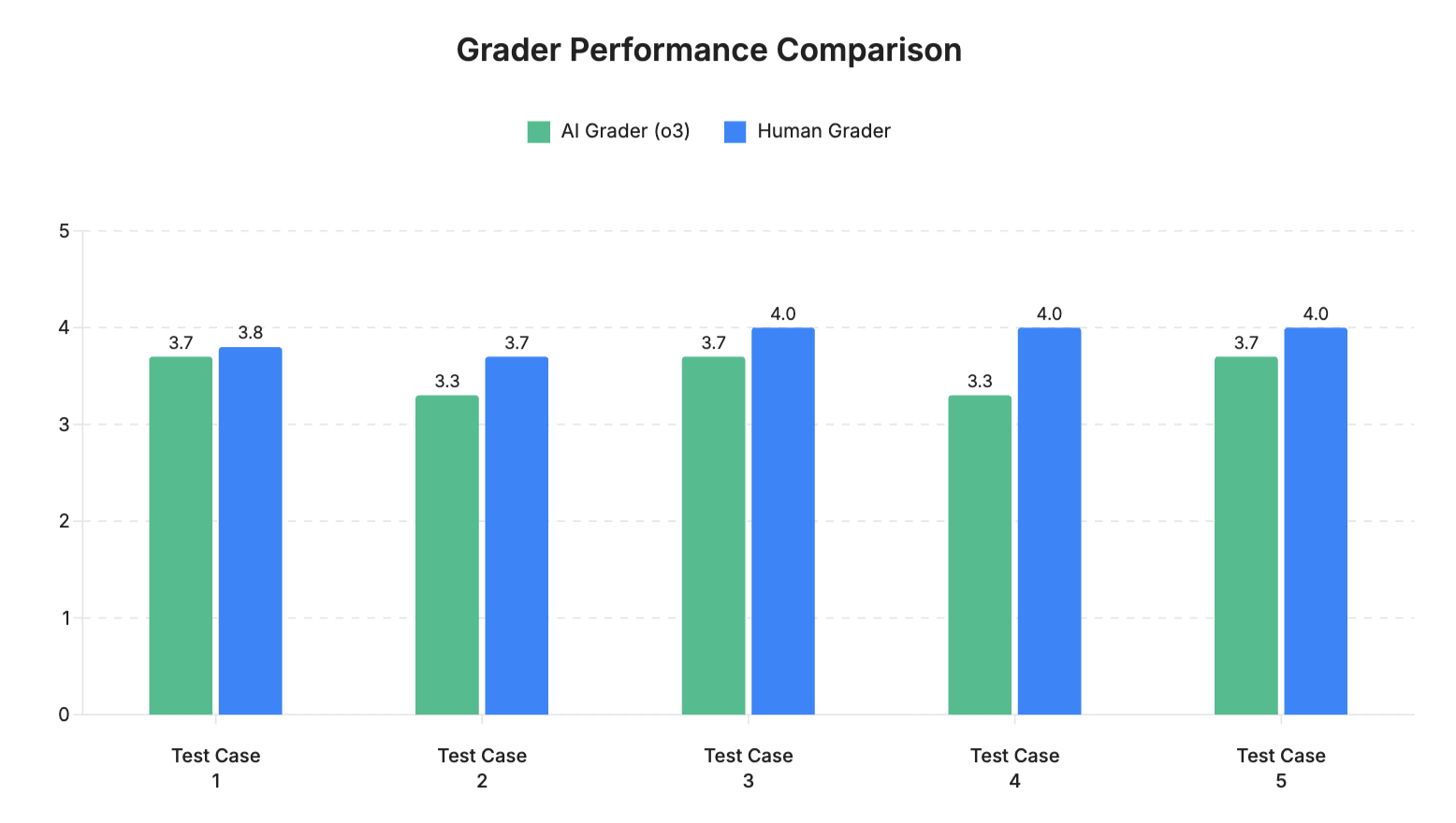
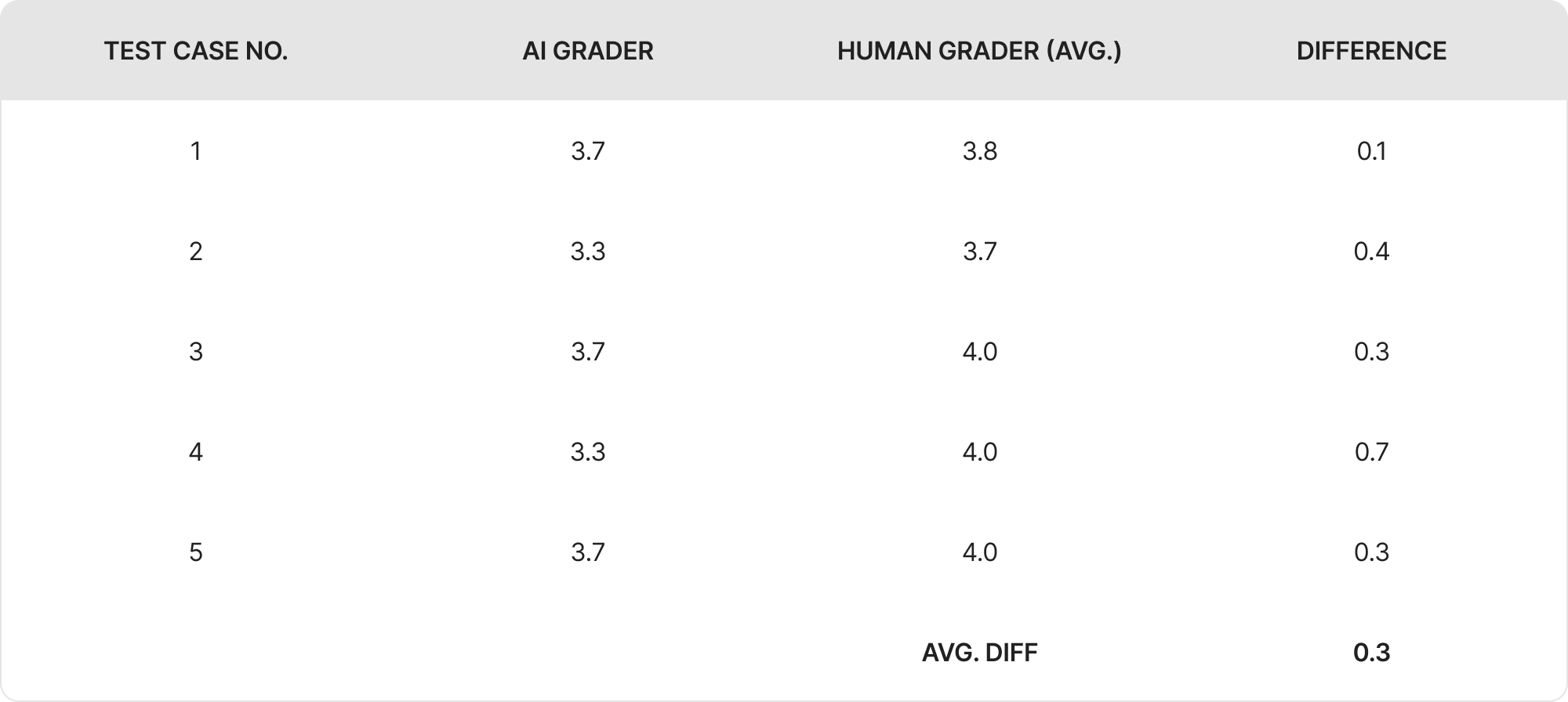
The grading performance of the AI evaluator (GPT model o3) was compared against human graders across five output samples. The scores for each output are illustrated in the graph and table below:
Grading Results Summary
Across five evaluated outputs, the AI grader showed a high level of alignment with the human grader, with only minor differences in scoring. The average score difference was 0.3 points, indicating that the AI's evaluations were generally consistent with human judgment.
- In most cases, AI scores were slightly more conservative than human scores.
- The largest gap was 0.7 points; the smallest was 0.1.
- Overall, the AI demonstrated reliable grading performance, suggesting its potential to support or automate parts of the evaluation process.
Collaborate and partner with our AI Lab at Amity Solutions here
